4.4 KiB
![]()
![]()
![]()
![]()

Silero VAD
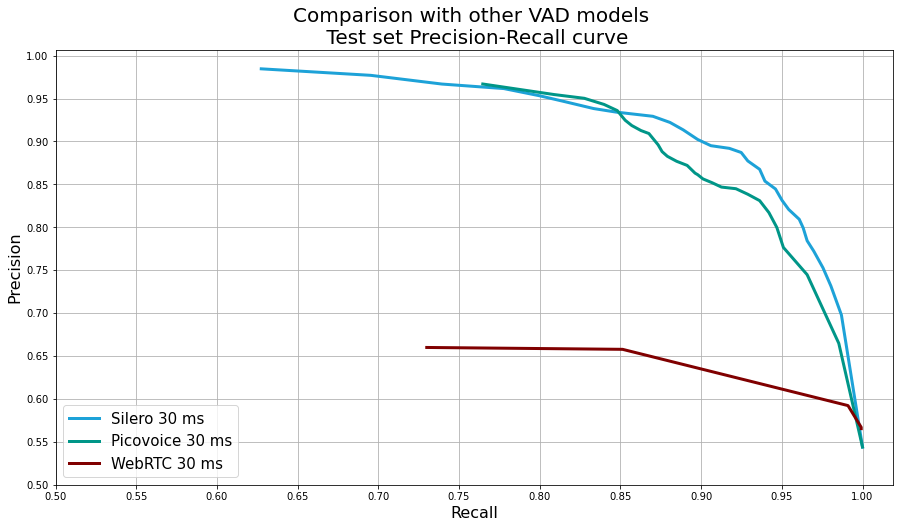
Silero VAD - pre-trained enterprise-grade Voice Activity Detector (also see our STT models).
Real Time Example
Key Features
-
High accuracy
Silero VAD shows an excellent result for speech detection in streaming tasks.
-
Fast
One audio chunk (30+ ms) takes 1ms to be processed on a single CPU thread. Using batching and/or GPU one can greatly speed up inference time in production tasks.
-
Lightweight
JIT model size is less than one megabyte.
-
Generalized
Silero VAD was trained on a big corpora that included over 100 languages and performs well on audio of varying backgorund noise levels.
-
Variable sampling rate
Silero VAD supports 8000 and 16000 sampling rate
-
Variable chunk size
Model was trained on audio chunks of variable lengths. Chunks of length 30 ms, 60 ms and 100 ms are supported directly, other may perform well too.
Typical Use Cases
- Voice activity detection for IOT / edge / mobile use cases
- Data cleaning and preparation, voice detection in general
Links
- Examples and Dependencies
- Quality Metrics
- Performance Metrics
- Number Detector and Language classifier models
- Versions and Available Models
Get In Touch
Try our models, create an issue, start a discussion, join our telegram chat, email us, read our news. Please see our wiki and tiers for relevant information and email us directly.
Please see our wiki and tiers for relevant information and email us directly.
Citations
@misc{Silero VAD,
author = {Silero Team},
title = {Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD), Number Detector and Language Classifier},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/snakers4/silero-vad}},
commit = {insert_some_commit_here},
email = {hello@silero.ai}
}