7.5 KiB
![]()
![]()
![]()
(coming soon)
![]()

Silero VAD
Single Image Why our VAD is better than WebRTC
Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD), Number Detector and Language Classifier. Enterprise-grade Speech Products made refreshingly simple (see our STT models).
Currently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector (link).
Also in enterprise it is crucial to be able to anonymize large-scale spoken corpora (i.e. remove personal data). Typically personal data is considered to be private / sensitive if it contains (i) a name (ii) some private ID. Name recognition is highly subjective and would depend on locale and business case, but Voice Activity and Number detections are quite general tasks.
Key features:
- Modern, portable;
- Lowe memory footprint;
- Superior metrics to WebRTC;
- Trained on huge spoken corpora and noise / sound libraries;
- Slower than WebRTC, but fast enough for IOT / edge / mobile applications;
Typical use cases:
- Spoken corpora anonymization;
- Voice activity detection for IOT / edge / mobile use cases;
- Data cleaning and preparation, number and voice detection in general;
Getting Started
The models are small enough to be included directly into this repository. Newer models will supersede older models directly.
Currently we provide the following functionality:
| PyTorch | ONNX | VAD | Number Detector | Language Clf | Languages | Colab |
|---|---|---|---|---|---|---|
| ✔️ | ✔️ | ✔️ | ru, en, de, es |
Version history:
| Version | Date | Comment |
|---|---|---|
v1 |
2020-12-15 | Initial release |
v2 |
coming soon | Add Number Detector or Language Classifier heads |
PyTorch
![]()
(coming soon)
import torch
torch.set_num_threads(1)
from pprint import pprint
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_ts,
_, read_audio,
_, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
wav = read_audio(f'{files_dir}/en.wav')
# full audio
# get speech timestamps from full audio file
speech_timestamps = get_speech_ts(wav, model,
num_steps=4)
pprint(speech_timestamps)
ONNX
![]()
You can run our model everywhere, where you can import the ONNX model or run ONNX runtime.
import onnxruntime
from pprint import pprint
_, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_ts,
_, read_audio,
_, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
def init_onnx_model(model_path: str):
return onnxruntime.InferenceSession(model_path)
def validate_onnx(model, inputs):
with torch.no_grad():
ort_inputs = {'input': inputs.cpu().numpy()}
outs = model.run(None, ort_inputs)
outs = [torch.Tensor(x) for x in outs]
return outs
model = init_onnx_model(f'{files_dir}/model.onnx')
wav = read_audio(f'{files_dir}/en.wav')
# get speech timestamps from full audio file
speech_timestamps = get_speech_ts(wav, model, num_steps=4, run_function=validate_onnx)
pprint(speech_timestamps)
Metrics
Performance Metrics
Speed metrics here.
Quality Metrics
We use random 0.25 second audio chunks to validate on. Speech to Non-speech ratio among chunks ~50/50, speech chunks are carved from real audios in four different languages (English, Russian, Spanish, German), then random random background noise is applied to some of them.
Since our models were trained on chunks of the same length, model's output is just one float number from 0 to 1 - speech probability. We use speech probabilities as tresholds for precision-recall curve.
Webrtc splits audio into frames, each frame has corresponding number (0 or 1). We use 30ms frames for webrtc predicts, so each 0.25 second chunk is splitted into 8 frames, their mean value is used as a treshold for plot.
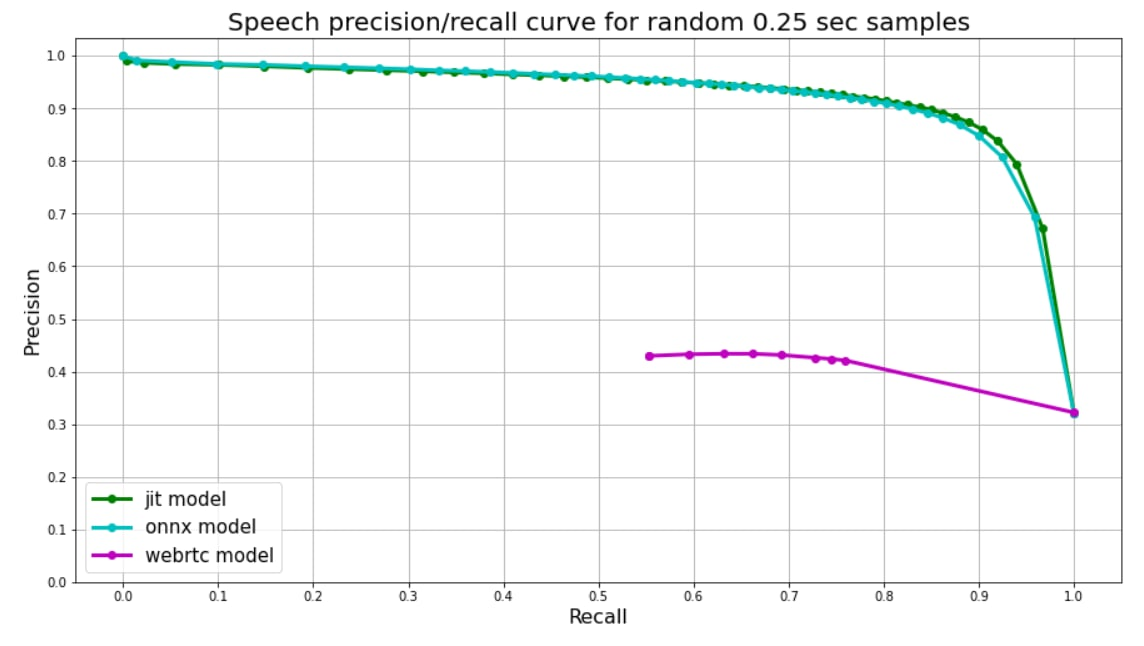
FAQ
How VAD Works
Bla-bla, 300ms, 15ms latency on 1 thread, see examples (naive, streaming).
VAD Quality Metrics Methodology
TBD
How Number Detector Works
TBD
How Language Classifier Works
TBD
Contact
Get in Touch
Try our models, create an issue, start a discussion, join our telegram chat, email us.
Commercial Inquiries
Please see our wiki and tiers for relevant information and email us directly.