mirror of
https://github.com/snakers4/silero-vad.git
synced 2026-02-05 18:09:22 +08:00
Update README.md
This commit is contained in:
@@ -24,8 +24,7 @@
|
||||
|
||||
|
||||
# Silero VAD
|
||||
|
||||

|
||||
|
||||
|
||||
**Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD), Number Detector and Language Classifier.**
|
||||
Enterprise-grade Speech Products made refreshingly simple (see our [STT](https://github.com/snakers4/silero-models) models).
|
||||
@@ -309,7 +308,9 @@ Since our VAD (only VAD, other networks are more flexible) was trained on chunks
|
||||
|
||||
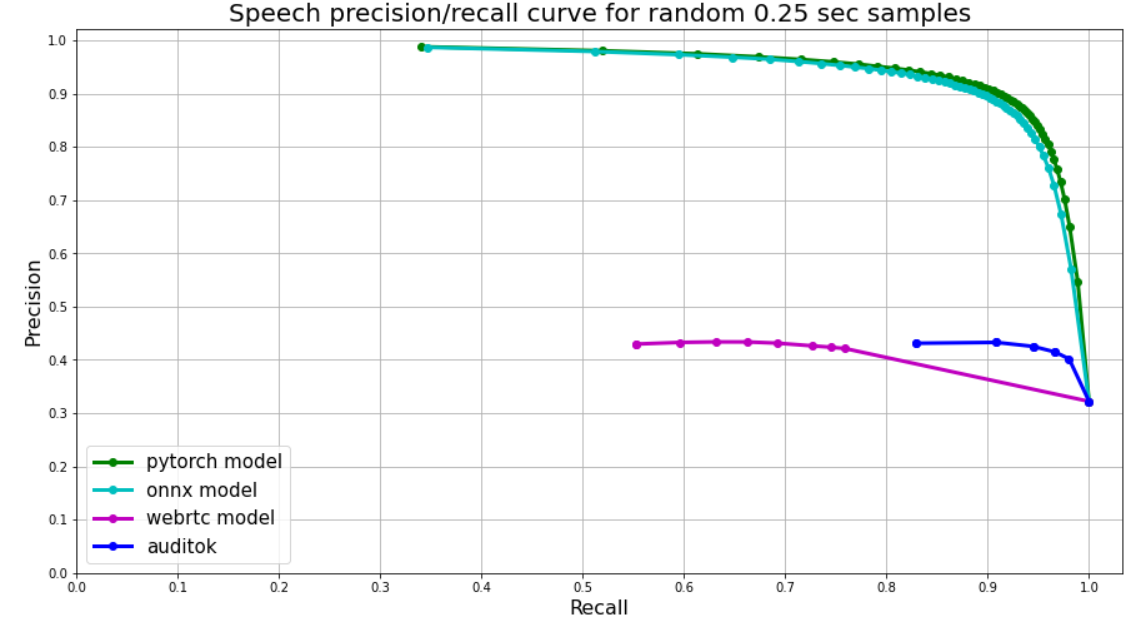
[Webrtc](https://github.com/wiseman/py-webrtcvad) splits audio into frames, each frame has corresponding number (0 **or** 1). We use 30ms frames for webrtc, so each 250 ms chunk is split into 8 frames, their **mean** value is used as a treshold for plot.
|
||||
|
||||

|
||||
[Auditok](https://github.com/amsehili/auditok) - logic same as Webrtc, but we use 50ms frames.
|
||||
|
||||

|
||||
|
||||
## FAQ
|
||||
|
||||
|
||||
Reference in New Issue
Block a user