mirror of
https://github.com/snakers4/silero-vad.git
synced 2026-02-05 18:09:22 +08:00
Update README.md
This commit is contained in:
@@ -97,7 +97,7 @@ We use random 0.25 second audio chunks to validate on. Speech to Non-speech rati
|
||||
|
||||
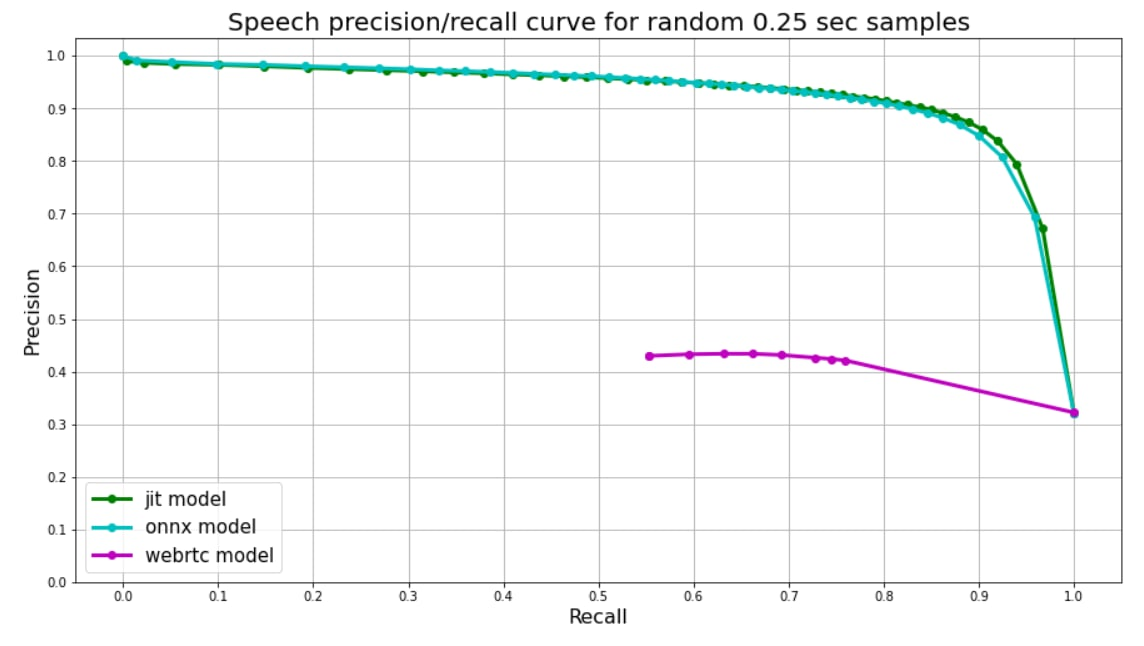
Since our models were trained on chunks of the same length, model's output is just one float number from 0 to 1 - **speech probability**. We use speech probabilities as tresholds for precision-recall curve.
|
||||
|
||||
Webrtc splits audio into frames, each frame has corresponding number (0 **or** 1). We use 30ms frames for webrtc predicts, so each 0.25 second chunk is splitted into 8 frames, their **mean** value is used as a treshold for plot.
|
||||
[Webrtc](https://github.com/wiseman/py-webrtcvad) splits audio into frames, each frame has corresponding number (0 **or** 1). We use 30ms frames for webrtc predicts, so each 0.25 second chunk is splitted into 8 frames, their **mean** value is used as a treshold for plot.
|
||||
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user