mirror of
https://github.com/snakers4/silero-vad.git
synced 2026-02-05 18:09:22 +08:00
Update README.md
This commit is contained in:
15
README.md
15
README.md
@@ -136,29 +136,30 @@ pprint(speech_timestamps)
|
||||
|
||||
### Performance Metrics
|
||||
|
||||
All speed test were made on SPECS using 1 thread
|
||||
All speed test were run on AMD Ryzen Threadripper 3960X using only 1 thread:
|
||||
```
|
||||
torch.set_num_threads(1) # pytorch
|
||||
ort_session.intra_op_num_threads = 1 # onnx
|
||||
ort_session.inter_op_num_threads = 1 # onnx
|
||||
```
|
||||
|
||||
#### Streaming speed
|
||||
#### Streaming Latency
|
||||
|
||||
Streaming speed depends on 2 variables:
|
||||
Streaming latency depends on 2 variables:
|
||||
|
||||
- **num_steps** - number of windows to split audio chunk by. Our postprocessing class keeps previous chunk in memory (250 ms), so new chunk (also 250 ms) appends to it, resulting big chunk (500 ms) is split into **num_steps** overlap windows, each 250 ms long.
|
||||
- **num_steps** - number of windows to split each audio chunk into. Our post-processing class keeps previous chunk in memory (250 ms), so new chunk (also 250 ms) is appended to it. The resulting big chunk (500 ms) is split into **num_steps** overlapping windows, each 250 ms long.
|
||||
|
||||
- **number of audio streams**
|
||||
|
||||
So **batch size** for streaming is **num_steps * number of audio streams**. Time between receiving new audio chunks from stream and getting results are shown in picture:
|
||||
So **batch size** for streaming is **num_steps * number of audio streams**. Time between receiving new audio chunks and getting results is shown in picture:
|
||||
|
||||
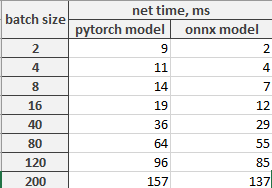
|
||||
|
||||
We are working on lifting this 250 ms constraint.
|
||||
|
||||
#### Full audio processing speed
|
||||
#### Full Audio Throughput
|
||||
|
||||
**RTS** (real time speed) for full audio processing depends on **num_steps** (see previous paragraph) and **batch size** (bigger is better)
|
||||
**RTS** (seconds of audio processed per second, real time speed, or 1 / RTF) for full audio processing depends on **num_steps** (see previous paragraph) and **batch size** (bigger is better).
|
||||
|
||||
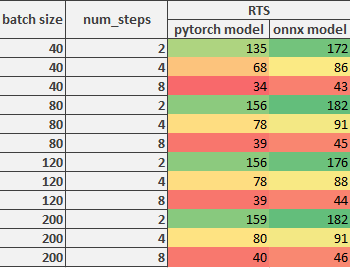
|
||||
|
||||
|
||||
Reference in New Issue
Block a user