mirror of
https://github.com/snakers4/silero-vad.git
synced 2026-02-05 18:09:22 +08:00
Polish readme
This commit is contained in:
45
README.md
45
README.md
@@ -1,6 +1,6 @@
|
||||
[](mailto:hello@silero.ai) [](https://t.me/joinchat/Bv9tjhpdXTI22OUgpOIIDg) [](https://github.com/snakers4/silero-vad/blob/master/LICENSE)
|
||||
|
||||
[](https://pytorch.org/hub/snakers4_silero-vad/)
|
||||
[](https://pytorch.org/hub/snakers4_silero-vad/) (coming soon)
|
||||
|
||||
[](https://colab.research.google.com/github/snakers4/silero-vad/blob/master/silero-vad.ipynb)
|
||||
|
||||
@@ -12,7 +12,7 @@
|
||||
- [ONNX](#onnx)
|
||||
- [Metrics](#metrics)
|
||||
- [Performance Metrics](#performance-metrics)
|
||||
- [Quality Metrics](#quality-metrics)
|
||||
- [VAD Quality Metrics](#vad-quality-metrics)
|
||||
- [FAQ](#faq)
|
||||
- [How VAD Works](#how-vad-works)
|
||||
- [VAD Quality Metrics Methodology](#vad-quality-metrics-methodology)
|
||||
@@ -25,28 +25,31 @@
|
||||
|
||||
# Silero VAD
|
||||
|
||||
`Single Image Why our VAD is better than WebRTC`
|
||||
|
||||
|
||||
Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD), Number Detector and Language Classifier.
|
||||
**Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD), Number Detector and Language Classifier.**
|
||||
Enterprise-grade Speech Products made refreshingly simple (see our [STT](https://github.com/snakers4/silero-models) models).
|
||||
|
||||
Currently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector ([link](https://github.com/wiseman/py-webrtcvad)).
|
||||
Currently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector ([link](https://github.com/wiseman/py-webrtcvad)). WebRTC though starts to show its age and it suffers from many false positives.
|
||||
|
||||
Also in enterprise it is crucial to be able to anonymize large-scale spoken corpora (i.e. remove personal data). Typically personal data is considered to be private / sensitive if it contains (i) a name (ii) some private ID. Name recognition is highly subjective and would depend on locale and business case, but Voice Activity and Number detections are quite general tasks.
|
||||
Also in some cases it is crucial to be able to anonymize large-scale spoken corpora (i.e. remove personal data). Typically personal data is considered to be private / sensitive if it contains (i) a name (ii) some private ID. Name recognition is a highly subjective matter and it depends on locale and business case, but Voice Activity and Number Detection are quite general tasks.
|
||||
|
||||
**Key features:**
|
||||
|
||||
- Modern, portable;
|
||||
- Lowe memory footprint;
|
||||
- Low memory footprint;
|
||||
- Superior metrics to WebRTC;
|
||||
- Trained on huge spoken corpora and noise / sound libraries;
|
||||
- Slower than WebRTC, but fast enough for IOT / edge / mobile applications;
|
||||
- Unlike WebRTC (which mostly tells silence from voice), our VAD can tell voice from noise / music / silence;
|
||||
|
||||
**Typical use cases:**
|
||||
|
||||
- Spoken corpora anonymization;
|
||||
- Can be used together with WebRTC;
|
||||
- Voice activity detection for IOT / edge / mobile use cases;
|
||||
- Data cleaning and preparation, number and voice detection in general;
|
||||
- Data cleaning and preparation, number and voice detection in general;
|
||||
- PyTorch and ONNX can be used with a wide variety of deployment options and backends in mind;
|
||||
|
||||
## Getting Started
|
||||
|
||||
@@ -62,8 +65,8 @@ Currently we provide the following functionality:
|
||||
|
||||
| Version | Date | Comment |
|
||||
|---------|-------------|---------------------------------------------------|
|
||||
| `v1` | 2020-12-15 | Initial release |
|
||||
| `v2` | coming soon | Add Number Detector or Language Classifier heads |
|
||||
| `v1` | 2020-12-15 | Initial release |
|
||||
| `v2` | coming soon | Add Number Detector or Language Classifier heads, lift 250 ms chunk VAD limitation |
|
||||
|
||||
### PyTorch
|
||||
|
||||
@@ -129,20 +132,19 @@ speech_timestamps = get_speech_ts(wav, model, num_steps=4, run_function=validate
|
||||
pprint(speech_timestamps)
|
||||
```
|
||||
|
||||
|
||||
## Metrics
|
||||
|
||||
### Performance Metrics
|
||||
|
||||
Speed metrics here.
|
||||
|
||||
### Quality Metrics
|
||||
### VAD Quality Metrics
|
||||
|
||||
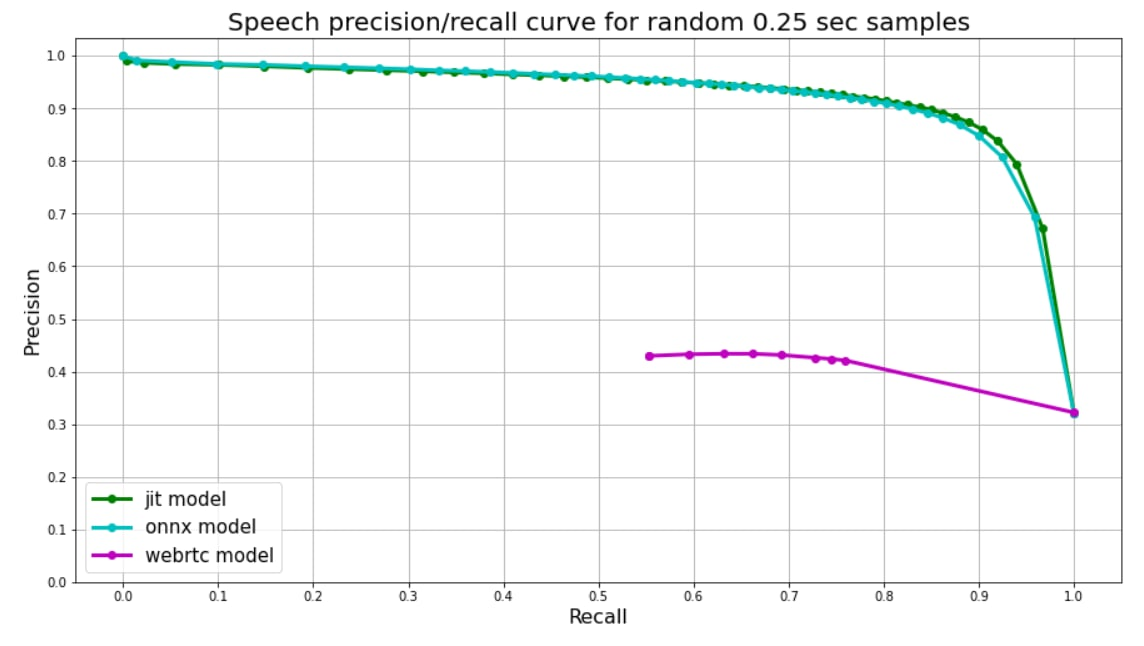
We use random 0.25 second audio chunks to validate on. Speech to Non-speech ratio among chunks ~50/50, speech chunks are carved from real audios in four different languages (English, Russian, Spanish, German), then random random background noise is applied to some of them.
|
||||
We use random 250 ms audio chunks for validation. Speech to non-speech ratio among chunks is about ~50/50 (i.e. balanced). Speech chunks are sampled from real audios in four different languages (English, Russian, Spanish, German), then random background noise is added to some of them (~40%).
|
||||
|
||||
Since our models were trained on chunks of the same length, model's output is just one float number from 0 to 1 - **speech probability**. We use speech probabilities as tresholds for precision-recall curve.
|
||||
Since our VAD (only VAD, other networks are more flexible) was trained on chunks of the same length, model's output is just one float from 0 to 1 - **speech probability**. We use speech probabilities as thresholds for precision-recall curve. This can be extended to 100 - 150 ms (coming soon). Less than 100 - 150 ms cannot be distinguished as speech with confidence.
|
||||
|
||||
[Webrtc](https://github.com/wiseman/py-webrtcvad) splits audio into frames, each frame has corresponding number (0 **or** 1). We use 30ms frames for webrtc predicts, so each 0.25 second chunk is splitted into 8 frames, their **mean** value is used as a treshold for plot.
|
||||
[Webrtc](https://github.com/wiseman/py-webrtcvad) splits audio into frames, each frame has corresponding number (0 **or** 1). We use 30ms frames for webrtc, so each 250 ms chunk is split into 8 frames, their **mean** value is used as a treshold for plot.
|
||||
|
||||

|
||||
|
||||
@@ -150,19 +152,24 @@ Since our models were trained on chunks of the same length, model's output is ju
|
||||
|
||||
### How VAD Works
|
||||
|
||||
Bla-bla, 300ms, 15ms latency on 1 thread, see examples (naive, streaming).
|
||||
- Audio is split into 250 ms chunks;
|
||||
- VAD keeps record of a previous chunk (or zeros at the beginning of the stream);
|
||||
- Then this 500 ms audio (250 ms + 250 ms) is split into N (typically 4 or 8) windows and the model is applied to this window batch. Each window is 250 ms long (naturally, windows overlap);
|
||||
- Then probability is averaged across these windows;
|
||||
- Though typically pauses in speech are 300 ms+ or longer (pauses less than 200-300ms are typically not meaninful), it is hard to confidently classify speech vs noise / music on very short chunks (i.e. 30 - 50ms);
|
||||
- We are working on lifting this limitation, so that you can use 100 - 125ms windows;
|
||||
|
||||
### VAD Quality Metrics Methodology
|
||||
|
||||
TBD
|
||||
Please see [Quality Metrics](#quality-metrics)
|
||||
|
||||
### How Number Detector Works
|
||||
|
||||
TBD
|
||||
TBD, but there is no explicit limiation on the way audio is split into chunks.
|
||||
|
||||
### How Language Classifier Works
|
||||
|
||||
TBD
|
||||
TBD, but there is no explicit limiation on the way audio is split into chunks.
|
||||
|
||||
## Contact
|
||||
|
||||
|
||||
Reference in New Issue
Block a user