diff --git a/README.md b/README.md
index 59cae76..5050042 100644
--- a/README.md
+++ b/README.md
@@ -15,7 +15,7 @@ This repository also includes Number Detector and Language classifier [models](h
- 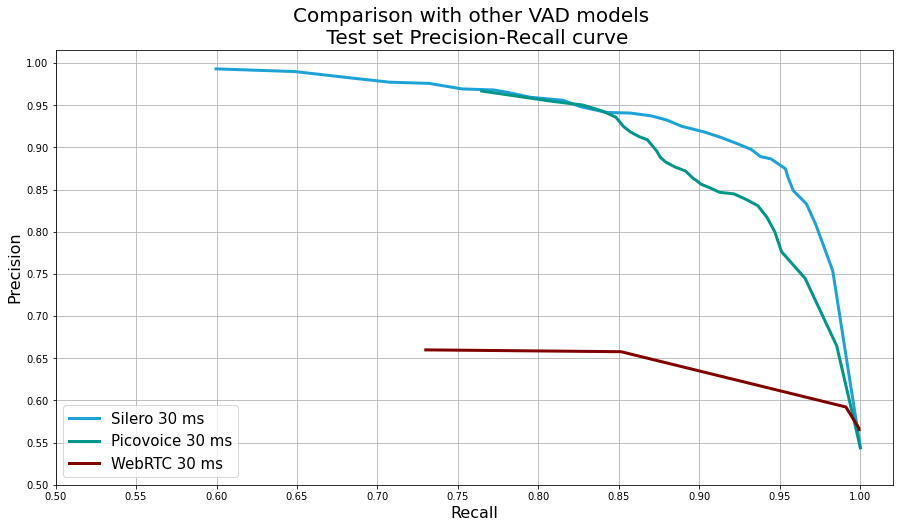 +
+ 
@@ -35,11 +35,11 @@ https://user-images.githubusercontent.com/36505480/144874384-95f80f6d-a4f1-42cc-
- **Fast**
- One audio chunk (30+ ms) [takes](https://github.com/snakers4/silero-vad/wiki/Performance-Metrics#silero-vad-performance-metrics) around **1ms** to be processed on a single CPU thread. Using batching or GPU can also improve performance considerably. Under certain conditions ONNX may even run up to 2-3x faster.
+ One audio chunk (30+ ms) [takes](https://github.com/snakers4/silero-vad/wiki/Performance-Metrics#silero-vad-performance-metrics) less than **1ms** to be processed on a single CPU thread. Using batching or GPU can also improve performance considerably. Under certain conditions ONNX may even run up to 4-5x faster.
- **Lightweight**
- JIT model is less than one megabyte in size.
+ JIT model is around one megabyte in size.
- **General**
@@ -47,11 +47,11 @@ https://user-images.githubusercontent.com/36505480/144874384-95f80f6d-a4f1-42cc-
- **Flexible sampling rate**
- Silero VAD [supports](https://github.com/snakers4/silero-vad/wiki/Quality-Metrics#sample-rate-comparison) **8000 Hz** and **16000 Hz** (PyTorch JIT) and **16000 Hz** (ONNX) [sampling rates](https://en.wikipedia.org/wiki/Sampling_(signal_processing)#Sampling_rate).
+ Silero VAD [supports](https://github.com/snakers4/silero-vad/wiki/Quality-Metrics#sample-rate-comparison) **8000 Hz** and **16000 Hz** [sampling rates](https://en.wikipedia.org/wiki/Sampling_(signal_processing)#Sampling_rate).
- **Flexible chunk size**
- Model was trained on audio chunks of different lengths. **30 ms**, **60 ms** and **100 ms** long chunks are supported directly, others may work as well.
+ Model was trained on **30 ms**. Longer chunks are supported directly, others may work as well.
- **Highly Portable**
diff --git a/files/silero_vad.jit b/files/silero_vad.jit
index e29f1e1..7eddfeb 100644
Binary files a/files/silero_vad.jit and b/files/silero_vad.jit differ
diff --git a/files/silero_vad.onnx b/files/silero_vad.onnx
index 127ffc9..ffbfbba 100644
Binary files a/files/silero_vad.onnx and b/files/silero_vad.onnx differ
diff --git a/utils_vad.py b/utils_vad.py
index e4fcfbf..46318af 100644
--- a/utils_vad.py
+++ b/utils_vad.py
@@ -9,7 +9,7 @@ languages = ['ru', 'en', 'de', 'es']
class OnnxWrapper():
- def __init__(self, path, force_onnx_cpu):
+ def __init__(self, path, force_onnx_cpu=False):
import numpy as np
global np
import onnxruntime
@@ -21,12 +21,9 @@ class OnnxWrapper():
self.session.inter_op_num_threads = 1
self.reset_states()
+ self.sample_rates = [8000, 16000]
- def reset_states(self):
- self._h = np.zeros((2, 1, 64)).astype('float32')
- self._c = np.zeros((2, 1, 64)).astype('float32')
-
- def __call__(self, x, sr: int):
+ def _validate_input(self, x, sr: int):
if x.dim() == 1:
x = x.unsqueeze(0)
if x.dim() > 2:
@@ -37,23 +34,62 @@ class OnnxWrapper():
x = x[::step]
sr = 16000
- if x.shape[0] > 1:
- raise ValueError("Onnx model does not support batching")
-
- if sr not in [16000]:
- raise ValueError(f"Supported sample rates: {[16000]}")
+ if sr not in self.sample_rates:
+ raise ValueError(f"Supported sampling rates: {self.sample_rates} (or multiply of 16000)")
if sr / x.shape[1] > 31.25:
raise ValueError("Input audio chunk is too short")
- ort_inputs = {'input': x.numpy(), 'h0': self._h, 'c0': self._c}
- ort_outs = self.session.run(None, ort_inputs)
- out, self._h, self._c = ort_outs
+ return x, sr
- out = torch.tensor(out).squeeze(2)[:, 1] # make output type match JIT analog
+ def reset_states(self, batch_size=1):
+ self._h = np.zeros((2, batch_size, 64)).astype('float32')
+ self._c = np.zeros((2, batch_size, 64)).astype('float32')
+ self._last_sr = 0
+ self._last_batch_size = 0
+ def __call__(self, x, sr: int):
+
+ x, sr = self._validate_input(x, sr)
+ batch_size = x.shape[0]
+
+ if not self._last_batch_size:
+ self.reset_states(batch_size)
+ if (self._last_sr) and (self._last_sr != sr):
+ self.reset_states(batch_size)
+ if (self._last_batch_size) and (self._last_batch_size != batch_size):
+ self.reset_states(batch_size)
+
+ if sr in [8000, 16000]:
+ ort_inputs = {'input': x.numpy(), 'h': self._h, 'c': self._c, 'sr': np.array(sr)}
+ ort_outs = self.session.run(None, ort_inputs)
+ out, self._h, self._c = ort_outs
+ else:
+ raise ValueError()
+
+ self._last_sr = sr
+ self._last_batch_size = batch_size
+
+ out = torch.tensor(out)
return out
+ def audio_forward(self, x, sr: int, num_samples: int = 512):
+ outs = []
+ x, sr = self._validate_input(x, sr)
+
+ if x.shape[1] % num_samples:
+ pad_num = num_samples - (x.shape[1] % num_samples)
+ x = torch.nn.functional.pad(x, (0, pad_num), 'constant', value=0.0)
+
+ self.reset_states(x.shape[0])
+ for i in range(0, x.shape[1], num_samples):
+ wavs_batch = x[:, i:i+num_samples]
+ out_chunk = self.__call__(wavs_batch, sr)
+ outs.append(out_chunk)
+
+ stacked = torch.cat(outs, dim=1)
+ return stacked.cpu()
+
class Validator():
def __init__(self, url, force_onnx_cpu):
@@ -128,7 +164,7 @@ def get_speech_timestamps(audio: torch.Tensor,
sampling_rate: int = 16000,
min_speech_duration_ms: int = 250,
min_silence_duration_ms: int = 100,
- window_size_samples: int = 1536,
+ window_size_samples: int = 512,
speech_pad_ms: int = 30,
return_seconds: bool = False,
visualize_probs: bool = False):