mirror of
https://github.com/snakers4/silero-vad.git
synced 2026-02-05 18:09:22 +08:00
Merge branch 'master' of github.com:snakers4/silero-vad
This commit is contained in:
88
README.md
88
README.md
@@ -13,6 +13,11 @@
|
|||||||
- [Metrics](#metrics)
|
- [Metrics](#metrics)
|
||||||
- [Performance Metrics](#performance-metrics)
|
- [Performance Metrics](#performance-metrics)
|
||||||
- [Quality Metrics](#quality-metrics)
|
- [Quality Metrics](#quality-metrics)
|
||||||
|
- [FAQ](#faq)
|
||||||
|
- [How VAD Works](#how-vad-works)
|
||||||
|
- [VAD Quality Metrics Methodology](#vad-quality-metrics-methodology)
|
||||||
|
- [How Number Detector Works](#how-number-detector-works)
|
||||||
|
- [How Language Classifier Works](#how-language-classifier-works)
|
||||||
- [Contact](#contact)
|
- [Contact](#contact)
|
||||||
- [Get in Touch](#get-in-touch)
|
- [Get in Touch](#get-in-touch)
|
||||||
- [Commercial Inquiries](#commercial-inquiries)
|
- [Commercial Inquiries](#commercial-inquiries)
|
||||||
@@ -57,7 +62,7 @@ Currently we provide the following functionality:
|
|||||||
|
|
||||||
| Version | Date | Comment |
|
| Version | Date | Comment |
|
||||||
|---------|-------------|---------------------------------------------------|
|
|---------|-------------|---------------------------------------------------|
|
||||||
| `v1` | 2020-12-15 | initial release |
|
| `v1` | 2020-12-15 | Initial release |
|
||||||
| `v2` | coming soon | Add Number Detector or Language Classifier heads |
|
| `v2` | coming soon | Add Number Detector or Language Classifier heads |
|
||||||
|
|
||||||
### PyTorch
|
### PyTorch
|
||||||
@@ -65,21 +70,66 @@ Currently we provide the following functionality:
|
|||||||
[](https://colab.research.google.com/github/snakers4/silero-vad/blob/master/silero-vad.ipynb)
|
[](https://colab.research.google.com/github/snakers4/silero-vad/blob/master/silero-vad.ipynb)
|
||||||
|
|
||||||
[](https://pytorch.org/hub/snakers4_silero-vad/) (coming soon)
|
[](https://pytorch.org/hub/snakers4_silero-vad/) (coming soon)
|
||||||
|
|
||||||
```python
|
```python
|
||||||
TBD
|
import torch
|
||||||
```
|
torch.set_num_threads(1)
|
||||||
|
from pprint import pprint
|
||||||
|
|
||||||
|
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
|
||||||
|
model='silero_vad',
|
||||||
|
force_reload=True)
|
||||||
|
|
||||||
|
(get_speech_ts,
|
||||||
|
_, read_audio,
|
||||||
|
_, _, _) = utils
|
||||||
|
|
||||||
|
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
|
||||||
|
|
||||||
|
wav = read_audio(f'{files_dir}/en.wav')
|
||||||
|
# full audio
|
||||||
|
# get speech timestamps from full audio file
|
||||||
|
speech_timestamps = get_speech_ts(wav, model,
|
||||||
|
num_steps=4)
|
||||||
|
pprint(speech_timestamps)
|
||||||
|
```
|
||||||
### ONNX
|
### ONNX
|
||||||
|
|
||||||
[](https://colab.research.google.com/github/snakers4/silero-vad/blob/master/silero-vad.ipynb)
|
[](https://colab.research.google.com/github/snakers4/silero-vad/blob/master/silero-vad.ipynb)
|
||||||
|
|
||||||
You can run our model everywhere, where you can import the ONNX model or run ONNX runtime.
|
You can run our model everywhere, where you can import the ONNX model or run ONNX runtime.
|
||||||
|
|
||||||
```python
|
```python
|
||||||
TBD
|
import onnxruntime
|
||||||
|
from pprint import pprint
|
||||||
|
|
||||||
|
_, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
|
||||||
|
model='silero_vad',
|
||||||
|
force_reload=True)
|
||||||
|
|
||||||
|
(get_speech_ts,
|
||||||
|
_, read_audio,
|
||||||
|
_, _, _) = utils
|
||||||
|
|
||||||
|
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
|
||||||
|
|
||||||
|
def init_onnx_model(model_path: str):
|
||||||
|
return onnxruntime.InferenceSession(model_path)
|
||||||
|
|
||||||
|
def validate_onnx(model, inputs):
|
||||||
|
with torch.no_grad():
|
||||||
|
ort_inputs = {'input': inputs.cpu().numpy()}
|
||||||
|
outs = model.run(None, ort_inputs)
|
||||||
|
outs = [torch.Tensor(x) for x in outs]
|
||||||
|
return outs
|
||||||
|
|
||||||
|
model = init_onnx_model(f'{files_dir}/model.onnx')
|
||||||
|
wav = read_audio(f'{files_dir}/en.wav')
|
||||||
|
|
||||||
|
# get speech timestamps from full audio file
|
||||||
|
speech_timestamps = get_speech_ts(wav, model, num_steps=4, run_function=validate_onnx)
|
||||||
|
pprint(speech_timestamps)
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
## Metrics
|
## Metrics
|
||||||
|
|
||||||
### Performance Metrics
|
### Performance Metrics
|
||||||
@@ -88,7 +138,31 @@ Speed metrics here.
|
|||||||
|
|
||||||
### Quality Metrics
|
### Quality Metrics
|
||||||
|
|
||||||
Quality metrics here.
|
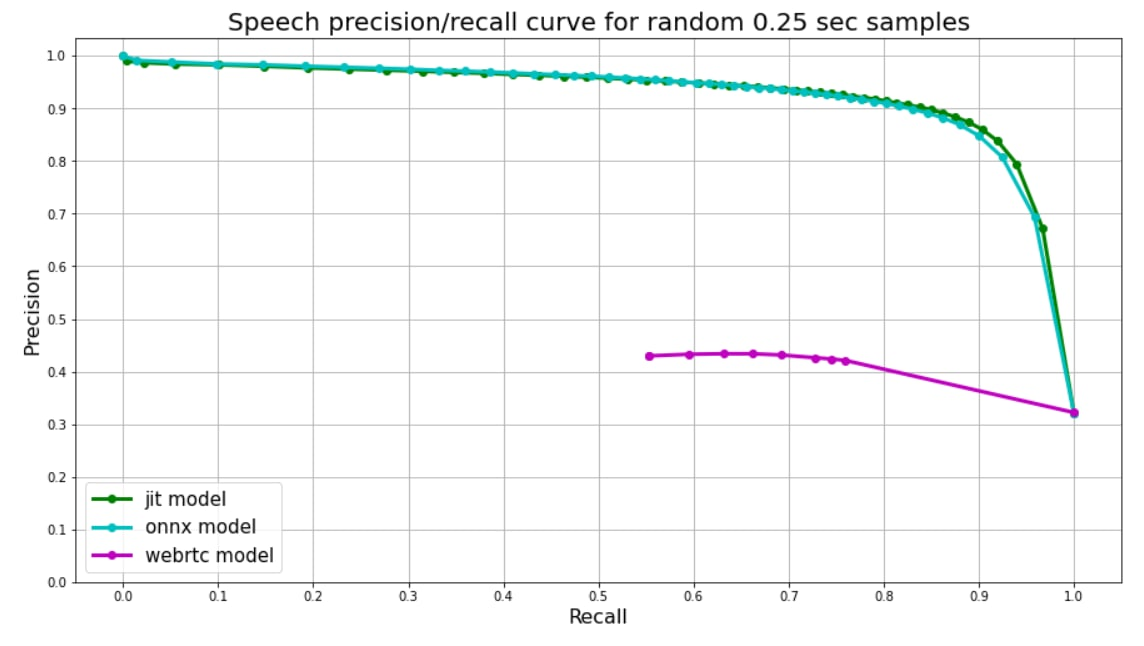
We use random 0.25 second audio chunks to validate on. Speech to Non-speech ratio among chunks ~50/50, speech chunks are carved from real audios in four different languages (English, Russian, Spanish, German), then random random background noise is applied to some of them.
|
||||||
|
|
||||||
|
Since our models were trained on chunks of the same length, model's output is just one float number from 0 to 1 - **speech probability**. We use speech probabilities as tresholds for precision-recall curve.
|
||||||
|
|
||||||
|
[Webrtc](https://github.com/wiseman/py-webrtcvad) splits audio into frames, each frame has corresponding number (0 **or** 1). We use 30ms frames for webrtc predicts, so each 0.25 second chunk is splitted into 8 frames, their **mean** value is used as a treshold for plot.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## FAQ
|
||||||
|
|
||||||
|
### How VAD Works
|
||||||
|
|
||||||
|
Bla-bla, 300ms, 15ms latency on 1 thread, see examples (naive, streaming).
|
||||||
|
|
||||||
|
### VAD Quality Metrics Methodology
|
||||||
|
|
||||||
|
TBD
|
||||||
|
|
||||||
|
### How Number Detector Works
|
||||||
|
|
||||||
|
TBD
|
||||||
|
|
||||||
|
### How Language Classifier Works
|
||||||
|
|
||||||
|
TBD
|
||||||
|
|
||||||
## Contact
|
## Contact
|
||||||
|
|
||||||
|
|||||||
Reference in New Issue
Block a user