
**性能领先且部署高效的多模态大模型**
OmniLMM-3B 🤗 🤖 |
OmniLMM-12B 🤗 🤖
**OmniLMM** 是面向图文理解的开源多模态大模型系列。该系列模型接受图像和文本输入,并提供高质量的文本输出。我们发布了两个版本的 OmniLMM,旨在实现**领先的性能和高效的部署**:
- **OmniLMM-12B**:相比同规模其他模型在多个基准测试中具有领先性能。
- **OmniLMM-3B**:可在终端设备上部署并具备先进的多模态对话能力。
[English Document](./README.md)
## 目录
- [目录](#目录)
- [OmniLMM-12B](#omnilmm-12b)
- [评测结果](#评测结果)
- [典型示例](#典型示例)
- [OmniLMM-3B](#omnilmm-3b)
- [性能评估](#性能评估)
- [部署示例](#部署示例)
- [Demo](#demo)
- [安装](#安装)
- [推理](#推理)
- [模型库](#模型库)
- [多轮对话](#多轮对话)
- [手机端部署](#手机端部署)
- [未来计划](#未来计划)
- [模型协议](#模型协议)
- [声明](#声明)
- [机构](#机构)
## OmniLMM-12B
**OmniLMM-12B** 是当前系列中性能最佳的版本。该模型基于EVA02-5B和Zephyr-7B-β初始化构建,并使用perceiver resampler连接,采用了课程学习的方法在多模态数据上进行训练。该模型具有三个特点:
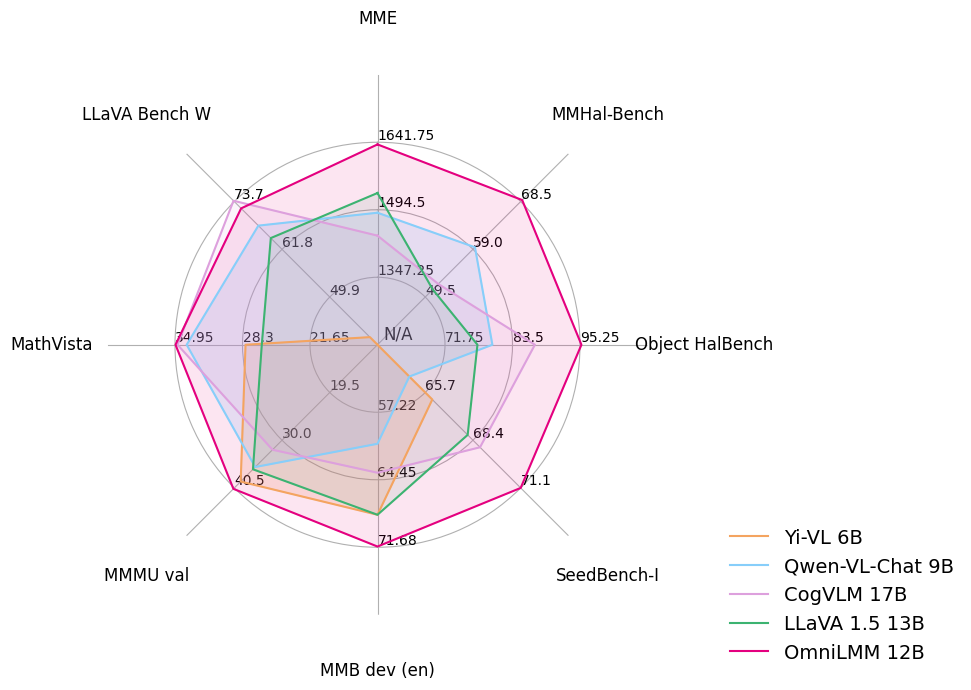
- 🔥 **性能领先。**
OmniLMM-12B 相比其他同规模模型在多个基准测试中取得**领先的性能**(包括 MME、MMBench、SEED-Bench 等),模型掌握了较为丰富的多模态世界知识。
- 🏆 **行为可信。**
多模态大模型的幻觉问题备受关注,模型经常生成和图像中的事实不符的文本(例如,确信地描述图片中并不存在的物体)。OmniLMM-12B是 **第一个通过多模态 RLHF 对齐的综合能力优秀的开源多模态大模型**(借助最新的 [RLHF-V](https://rlhf-v.github.io/) 技术)。该模型在 [MMHal-Bench](https://huggingface.co/datasets/Shengcao1006/MMHal-Bench) 幻觉评测基准上达到**开源模型最佳水平**,并在 [Object HalBench](https://arxiv.org/abs/2312.00849) 中**优于GPT-4V**。
- 🕹 **实时多模态交互。**
我们尝试结合OmniLMM-12B和GPT-3.5 (纯文本模型) ,实现**实时多模态交互助手**。该模型接受来自摄像头的视频流,并借助工具处理语音输入输出。虽然还很初步,我们发现该模型无需视频编辑可以**复现Gemini演示视频中的一些有趣例子**。
### 评测结果

 [清华大学自然语言处理实验室](https://nlp.csai.tsinghua.edu.cn/)
-
[清华大学自然语言处理实验室](https://nlp.csai.tsinghua.edu.cn/)
-  [面壁智能](https://modelbest.cn/)
-
[面壁智能](https://modelbest.cn/)
-  [知乎](https://www.zhihu.com/ )
[知乎](https://www.zhihu.com/ )


