
**Large multi-modal models for strong performance and efficient deployment**
[中文](./README_zh.md) |
English
MiniCPM-V 2.0 🤗 🤖 |
OmniLMM-12B 🤗 🤖
**MiniCPM-V** and **OmniLMM** are a family of open-source large multimodal models (LMMs) adept at vision & language modeling. The models process images and text inputs and deliver high-quality text outputs. We release two featured versions that are targeted at **strong performance and efficient deployment**:
- **MiniCPM-V 2.8B**: State-of-the-art end-side large multimodal models. Our latest MiniCPM-V 2.0 can accept 1.8 million pixels (e.g., 1344x1344) images at any aspect ratio, and is adept at OCR capability. It achieves comparable performance with Gemini Pro in understanding scene-text and matches GPT-4V in preventing hallucinations.
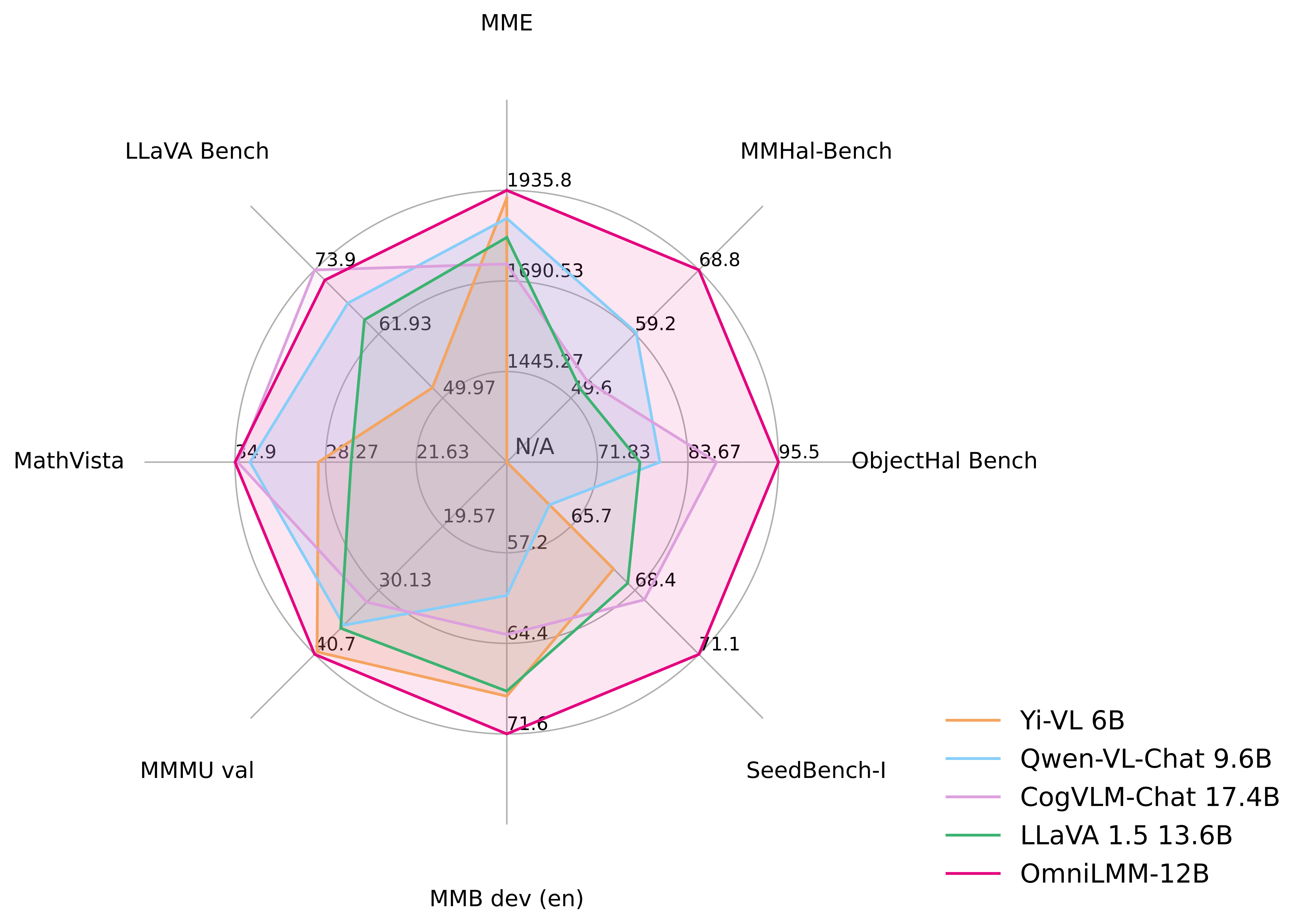
- **OmniLMM 12B**: The most capable version with leading performance among comparable-sized models on multiple benchmarks. The model also achieves state-of-the-art performance in trustworthy behaviors, with even less hallucination than GPT-4V.
[中文文档](./README_zh.md)
## Contents
- [MiniCPM-V 2.8B](#minicpm-v-28b)
- [OmniLMM-12B](#omnilmm-12b)
- [Demo](#demo)
- [Install](#install)
- [Inference](#inference)
- [Model Zoo](#model-zoo)
- [Multi-turn Conversation](#multi-turn-conversation)
- [Inference on Mac](#inference-on-mac)
- [Deployment on Mobile Phone](#deployment-on-mobile-phone)
- [TODO](#todo)
## MiniCPM-V 2.8B
**MiniCPM-V 2.8B** is an efficient version with promising performance for deployment. The model is built based on SigLip-400M and [MiniCPM-2.4B](https://github.com/OpenBMB/MiniCPM/), connected by a perceiver resampler. Our latest version, MiniCPM-V 2.0 has several notable features.
- 🔥 **State-of-the-art Performance.**
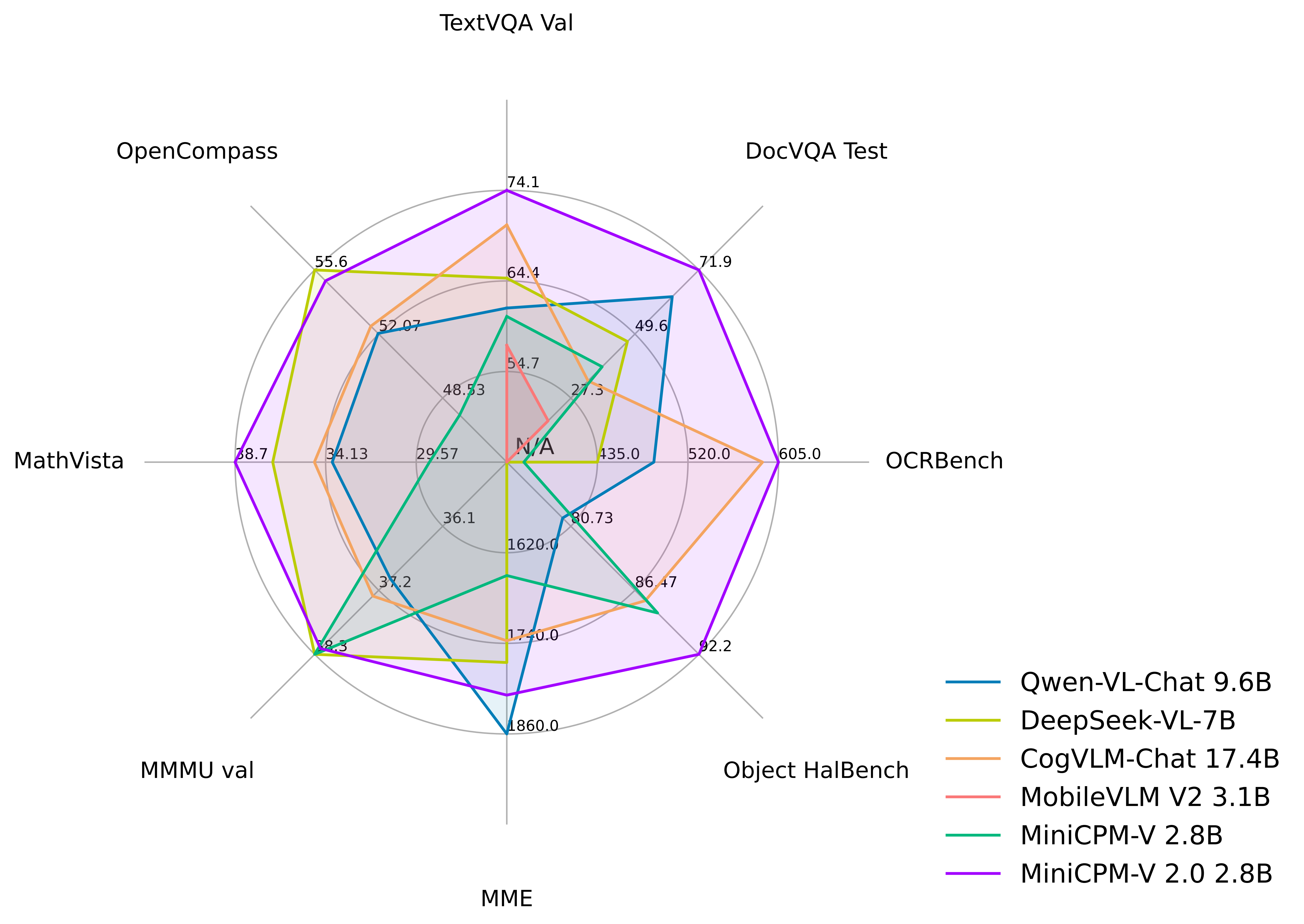
MiniCPM-V 2.0 achieves **state-of-the-art performance** on multiple benchmarks (including OCRBench, TextVQA, MME, MMB, MathVista, etc) among models under 7B parameters. It even **outperforms strong Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on OpenCompass, a comprehensive evaluation over 11 popular benchmarks**. Notably, MiniCPM-V 2.0 shows **strong OCR capability**, achieving **comparable performance to Gemini Pro in scene-text understanding**, and **state-of-the-art performance on OCRBench** among open-source models.
- 🏆 **Trustworthy Behavior.**
LMMs are known for suffering from hallucination, often generating text not factually grounded in images. MiniCPM-V 2.0 is **the first end-side LMM aligned via multimodal RLHF for trustworthy behavior** (using the recent [RLHF-V](https://rlhf-v.github.io/) [CVPR'24] series technique). This allows the model to **match GPT-4V in preventing hallucinations** on Object HalBench.
- 🌟 **High-Resolution Images at Any Aspect Raito.**
MiniCPM-V 2.0 can accept **1.8 million pixels (e.g., 1344x1344) images at any aspect ratio**. This enables better perception of fine-grained visual information such as small objects and optical characters, which is achieved via a recent technique from [LLaVA-UHD](https://arxiv.org/pdf/2403.11703.pdf).
- ⚡️ **High Efficiency.**
MiniCPM-V 2.0 can be **efficiently deployed on most GPU cards and personal computers**, and **even on end devices such as mobile phones**. For visual encoding, we compress the image representations into much fewer tokens via a perceiver resampler. This allows MiniCPM-V 2.0 to operate with **favorable memory cost and speed during inference even when dealing with high-resolution images**.
- 🙌 **Bilingual Support.**
MiniCPM-V 2.0 **supports strong bilingual multimodal capabilities in both English and Chinese**. This is enabled by generalizing multimodal capabilities across languages, a technique from [VisCPM](https://arxiv.org/abs/2308.12038) [ICLR'24].
### Evaluation

 [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-
[THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-  [ModelBest](https://modelbest.cn/)
-
[ModelBest](https://modelbest.cn/)
-  [Zhihu](https://www.zhihu.com/ )
[Zhihu](https://www.zhihu.com/ )



