**MiniCPM-V**和**OmniLMM** 是面向图文理解的开源多模态大模型系列。该系列模型接受图像和文本输入,并提供高质量的文本输出。我们发布了两个版本的模型,旨在实现**领先的性能和高效的部署**:
- **MiniCPM-V 2.8B**:可在终端设备上部署的先进多模态大模型。最新发布的 MiniCPM-V 2.0 可以接受 180 万像素的任意长宽比图像输入,实现了和 Gemini Pro 相近的场景文字识别能力以及和 GPT-4V 相匹的低幻觉率。
- **OmniLMM-12B**:相比同规模其他模型在多个基准测试中具有领先性能,实现了相比 GPT-4V 更低的幻觉率。
## 更新日志
* [2024.04.12] 我们开源了 MiniCPM-V 2.0,该模型刷新了 OCRBench 开源模型最佳成绩,在场景文字识别能力上比肩 Gemini Pro,同时还在综合了 11 个主流多模态大模型评测基准的 OpenCompass 榜单上超过了 Qwen-VL-Chat 10B、CogVLM-Chat 17B 和 Yi-VL 34B 等更大参数规模的模型!点击这里查看 MiniCPM-V 2.0 技术博客。
* [2024.03.14] MiniCPM-V 现在支持 SWIFT 框架下的[微调](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md)了,感谢 [Jintao](https://github.com/Jintao-Huang) 的贡献!
* [2024.03.01] MiniCPM-V 现在支持在 Mac 电脑上进行部署!
* [2024.02.01] 我们开源了 MiniCPM-V 和 OmniLMM-12B,分别可以支持高效的端侧部署和同规模领先的多模态能力!
## 目录
- [MiniCPM-V 2.8B](#minicpm-v-28b)
- [OmniLMM-12B](#omnilmm-12b)
- [Demo](#demo)
- [安装](#安装)
- [推理](#推理)
- [模型库](#模型库)
- [多轮对话](#多轮对话)
- [Mac 推理](#mac-推理)
- [手机端部署](#手机端部署)
- [未来计划](#未来计划)
## MiniCPM-V 2.8B
**MiniCPM-V 2.8B**可以高效部署到终端设备。该模型基于 SigLip-400M 和 [MiniCPM-2.4B](https://github.com/OpenBMB/MiniCPM/)构建,通过perceiver resampler连接。最新发布的 MiniCPM-V 2.0 的特点包括:
- 🔥 **优秀的性能。**
MiniCPM-V 2.0 在多个测试基准(如 OCRBench, TextVQA, MME, MMB, MathVista 等)中实现了 7B 以下模型的**最佳性能**。**在综合了 11 个主流多模态大模型评测基准的 OpenCompass 榜单上超过了 Qwen-VL-Chat 9.6B、CogVLM-Chat 17.4B 和 Yi-VL 34B 等更大参数规模的模型**。MiniCPM-V 2.0 还展现出**领先的 OCR 能力**,在场景文字识别能力上**接近 Gemini Pro**,OCRBench 得分达到**开源模型第一**。
- 🏆 **可信行为。**
多模态大模型深受幻觉问题困扰,模型经常生成和图像中的事实不符的文本。MiniCPM-V 2.0 是 **第一个通过多模态 RLHF 对齐的端侧多模态大模型**(借助 [RLHF-V](https://rlhf-v.github.io/) [CVPR'24] 系列技术)。该模型在 [Object HalBench](https://arxiv.org/abs/2312.00849) 达到**和 GPT-4V 相仿**的性能。
- 🌟 **高清图像高效编码。**
MiniCPM-V 2.0 可以接受 **180 万像素的任意长宽比图像输入**(基于最新的[LLaVA-UHD](https://arxiv.org/pdf/2403.11703.pdf) 技术),这使得模型可以感知到小物体、密集文字等更加细粒度的视觉信息。
- ⚡️ **高效部署。**
MiniCPM-V 2.0 可以**高效部署在大多数消费级显卡和个人电脑上**,包括**移动手机等终端设备**。在视觉编码方面,我们通过perceiver resampler将图像表示压缩为更少的 token。这使得 MiniCPM-V 2.0 即便是**面对高分辨率图像,也能占用较低的存储并展现优秀的推理速度**。
- 🙌 **双语支持。**
MiniCPM-V 2.0 **提供领先的中英双语多模态能力支持**。
该能力通过 [VisCPM](https://arxiv.org/abs/2308.12038) [ICLR'24] 论文中提出的多模态能力的跨语言泛化技术实现。
### 性能评估
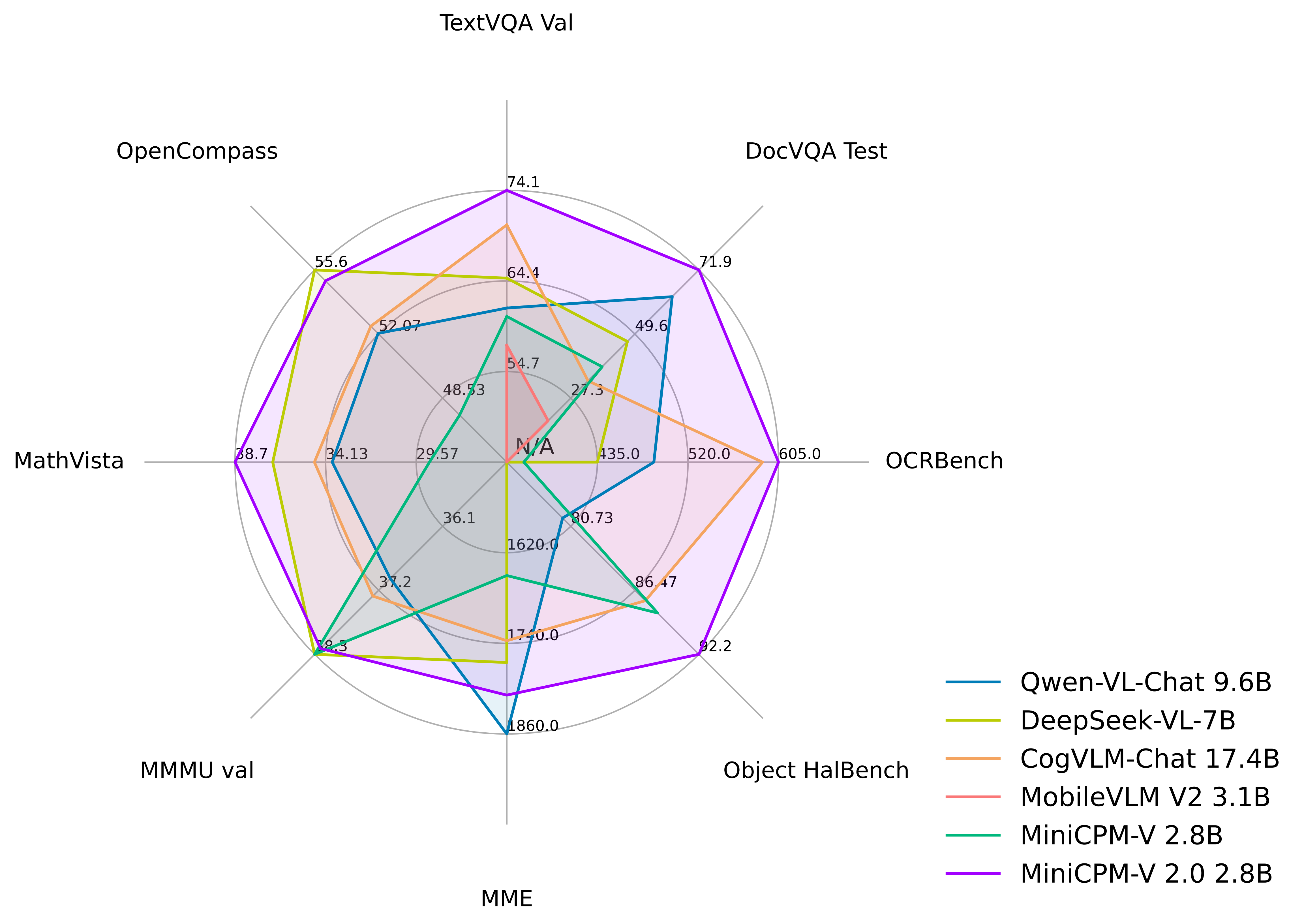
TextVQA, DocVQA, OCRBench, OpenCompass, MME, MMBench, MMMU, MathVista, LLaVA Bench, Object HalBench 上的详细评测结果。
| Model |
Size |
TextVQA val |
DocVQA test |
OCRBench |
OpenCompass |
MME |
MMB dev(en) |
MMB dev(zh) |
MMMU val |
MathVista |
LLaVA Bench |
Object HalBench |
| Proprietary models |
| Gemini Pro Vision |
- |
74.6 |
88.1 |
680 |
63.8 |
2148.9 |
75.2 |
74.0 |
48.9 |
45.8 |
79.9 |
- |
| GPT-4V |
- |
78.0 |
88.4 |
645 |
63.2 |
1771.5 |
75.1 |
75.0 |
53.8 |
47.8 |
93.1 |
86.4 / 92.7 |
| Open-source models 6B~34B |
| Yi-VL-6B |
6.7B |
45.5* |
17.1* |
290 |
49.3 |
1915.1 |
68.6 |
68.3 |
40.3 |
28.8 |
51.9 |
- |
| Qwen-VL-Chat |
9.6B |
61.5 |
62.6 |
488 |
52.1 |
1860.0 |
60.6 |
56.7 |
37.0 |
33.8 |
67.7 |
56.2 / 80.0 |
| Yi-VL-34B |
34B |
43.4* |
16.9* |
290 |
52.6 |
2050.2 |
71.1 |
71.4 |
45.1 |
30.7 |
62.3 |
- |
| DeepSeek-VL-7B |
7.3B |
64.7* |
47.0* |
435 |
55.6 |
1765.4 |
74.1 |
72.8 |
38.3 |
36.8 |
77.8 |
- |
| TextMonkey |
9.7B |
64.3 |
66.7 |
558 |
- |
- |
- |
- |
- |
- |
- |
- |
| CogVLM-Chat |
17.4B |
70.4 |
33.3* |
590 |
52.5 |
1736.6 |
63.7 |
53.8 |
37.3 |
34.7 |
73.9 |
73.6 / 87.4 |
| Open-source models 1B~3B |
| DeepSeek-VL-1.3B |
1.7B |
58.4* |
37.9* |
413 |
46.0 |
1531.6 |
64.0 |
61.2 |
33.8 |
29.4 |
51.1 |
- |
| MobileVLM V2 |
3.1B |
57.5 |
19.4* |
- |
- |
1440.5(P) |
63.2 |
- |
- |
- |
- |
- |
| Mini-Gemini |
2.2B |
56.2 |
34.2* |
- |
- |
1653.0 |
59.8 |
- |
31.7 |
- |
- |
- |
| MiniCPM-V |
2.8B |
60.6 |
38.2 |
366 |
47.6 |
1650.2 |
67.9 |
65.3 |
38.3 |
28.9 |
51.3 |
78.4 / 88.5 |
| MiniCPM-V 2.0 |
2.8B |
74.1 |
71.9 |
605 |
55.0 |
1808.6 |
69.6 |
68.1 |
38.2 |
38.7 |
69.2 |
85.5 / 92.2 |
* 我们自己评测了正式开源的模型权重。
### 典型示例

我们将 MiniCPM-V 2.0 部署在小米 14 Pro 上,并录制了以下演示视频,未经任何视频剪辑。


### MiniCPM-V 1.0
请参考[这里](./minicpm_v1.md)了解 MiniCPM-V 1.0 的信息和使用教程。
## OmniLMM-12B
**OmniLMM-12B** 是当前系列中性能最佳的版本。该模型基于EVA02-5B和Zephyr-7B-β初始化构建,并使用perceiver resampler连接,采用了课程学习的方法在多模态数据上进行训练。该模型具有三个特点:
- 🔥 **性能领先。**
OmniLMM-12B 相比其他同规模模型在多个基准测试中取得**领先的性能**(包括 MME、MMBench、SEED-Bench 等),模型掌握了较为丰富的多模态世界知识。
- 🏆 **行为可信。**
多模态大模型的幻觉问题备受关注,模型经常生成和图像中的事实不符的文本(例如,确信地描述图片中并不存在的物体)。OmniLMM-12B是 **第一个通过多模态 RLHF 对齐的综合能力优秀的开源多模态大模型**(借助 [RLHF-V](https://rlhf-v.github.io/) [CVPR'24] 系列技术)。该模型在 [MMHal-Bench](https://huggingface.co/datasets/Shengcao1006/MMHal-Bench) 幻觉评测基准上达到**开源模型最佳水平**,并在 [Object HalBench](https://arxiv.org/abs/2312.00849) 中**优于GPT-4V**。
- 🕹 **实时多模态交互。**
我们尝试结合OmniLMM-12B和GPT-3.5 (纯文本模型) ,实现**实时多模态交互助手**。该模型接受来自摄像头的视频流,并借助工具处理语音输入输出。虽然还很初步,我们发现该模型无需视频编辑可以**复现Gemini演示视频中的一些有趣例子**。
### 评测结果
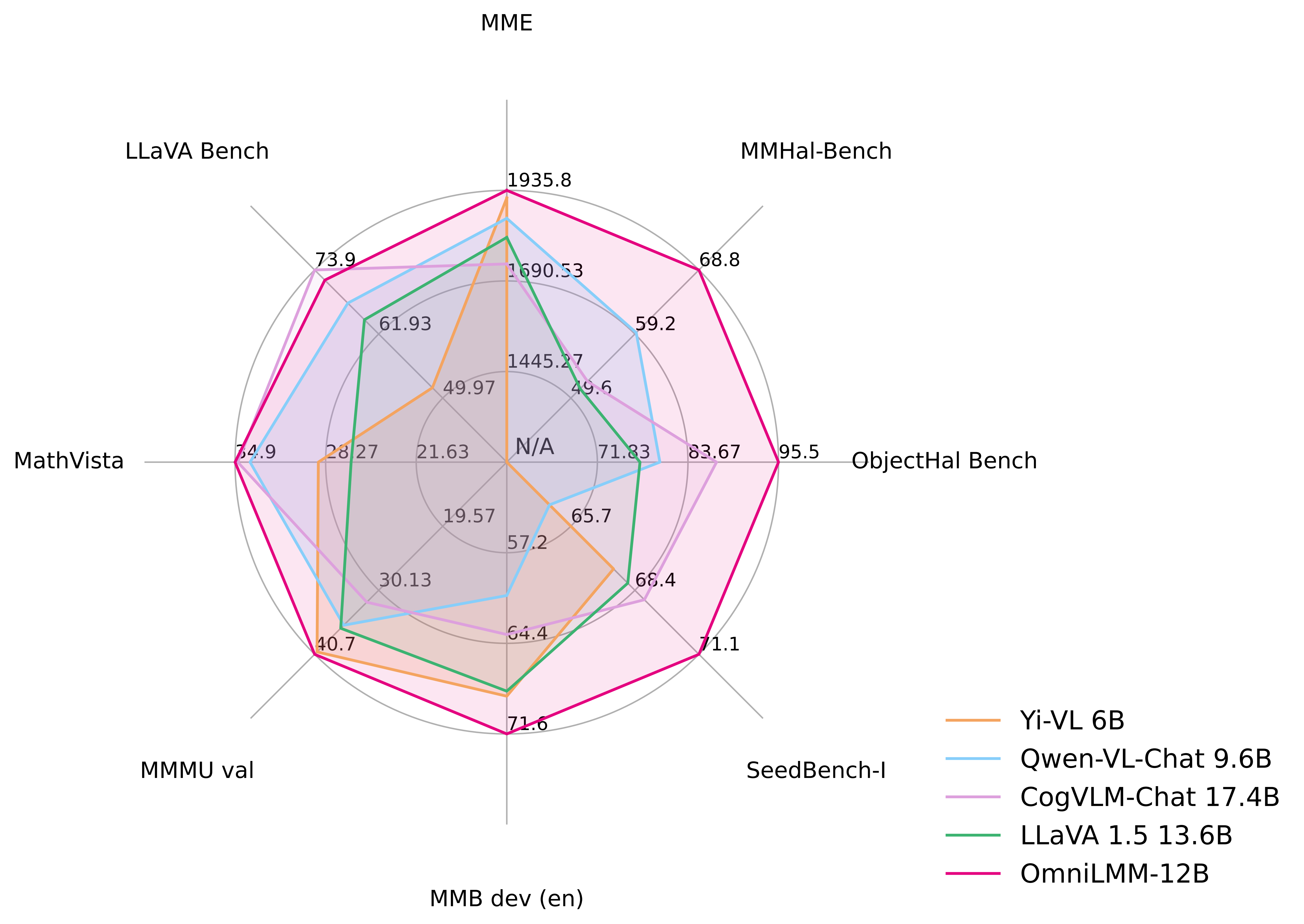
MME, MMBench, MMMU, MMBench, MMHal-Bench, Object HalBench, SeedBench, LLaVA Bench W, MathVista 上的详细评测结果。
| Model |
Size |
MME |
MMB dev (en) |
MMMU val |
MMHal-Bench |
Object HalBench |
SeedBench-I |
MathVista |
LLaVA Bench |
| GPT-4V† |
- |
1771.5 |
75.1 |
56.8 |
3.53 / 70.8 |
86.4 / 92.7 |
71.6 |
47.8 |
93.1 |
| Qwen-VL-Plus† |
- |
2183.4 |
66.2 |
45.2 |
- |
- |
65.7 |
36.0 |
73.7 |
| Yi-VL 6B |
6.7B |
1915.1 |
68.6 |
40.3 |
- |
- |
67.5 |
28.8 |
51.9 |
| Qwen-VL-Chat |
9.6B |
1860.0 |
60.6 |
35.9 |
2.93 / 59.4 |
56.2 / 80.0 |
64.8 |
33.8 |
67.7 |
| CogVLM-Chat |
17.4B |
1736.6 |
63.7 |
32.1 |
2.68 / 52.1 |
73.6 / 87.4 |
68.8 |
34.7 |
73.9 |
| LLaVA 1.5 |
13.6B |
1808.4 |
68.2 |
36.4 |
2.71 / 51.0 |
53.7 / 77.4 |
68.1 |
26.4 |
64.6 |
| OmniLMM-12B |
11.6B |
1935.8 |
71.6 |
40.7 |
3.45 / 68.8 |
90.3 / 95.5 |
71.1 |
34.9 |
72.0 |
†: 闭源模型
### 典型示例

我们结合 OmniLMM-12B 和 ChatGPT-3.5 (纯文本模型) 尝试构建 **实时多模态交互助手**. OmniLMM-12B 将视频帧转为对应的图像描述并输入给ChatGPT-3.5来生成对用户指令的响应。演示视频未经编辑。
## Demo
欢迎通过以下链接使用我们的网页端推理服务: [OmniLMM-12B](http://120.92.209.146:8081) | [MiniCPM-V 2.0](http://120.92.209.146:80).
## 安装
1. 克隆我们的仓库并跳转到相应目录
```bash
git clone https://github.com/OpenBMB/OmniLMM.git
cd OmniLMM
```
1. 创建 conda 环境
```Shell
conda create -n OmniLMM python=3.10 -y
conda activate OmniLMM
```
3. 安装依赖
```shell
pip install -r requirements.txt
```
## 推理
### 模型库
| 模型 | 简介 | 下载链接 |
|:----------------------|:-------------------|:---------------:|
| MiniCPM-V 2.0 | 最新版本,提供高效而领先的端侧双语多模态理解能力。 | [🤗](https://huggingface.co/openbmb/MiniCPM-V-2.0) [ ](https://modelscope.cn/models/OpenBMB/MiniCPM-V-2.0/files) |
| MiniCPM-V | 第一版 MiniCPM-V | [🤗](https://huggingface.co/openbmb/MiniCPM-V) [](https://modelscope.cn/models/OpenBMB/MiniCPM-V/files) |
| OmniLMM-12B | 性能最强的版本 | [🤗](https://huggingface.co/openbmb/OmniLMM-12B) [](https://modelscope.cn/models/OpenBMB/OmniLMM-12B/files) |
### 多轮对话
请参考以下代码使用 `MiniCPM-V` 和 `OmniLMM` 进行推理。
](https://modelscope.cn/models/OpenBMB/MiniCPM-V-2.0/files) |
| MiniCPM-V | 第一版 MiniCPM-V | [🤗](https://huggingface.co/openbmb/MiniCPM-V) [](https://modelscope.cn/models/OpenBMB/MiniCPM-V/files) |
| OmniLMM-12B | 性能最强的版本 | [🤗](https://huggingface.co/openbmb/OmniLMM-12B) [](https://modelscope.cn/models/OpenBMB/OmniLMM-12B/files) |
### 多轮对话
请参考以下代码使用 `MiniCPM-V` 和 `OmniLMM` 进行推理。

```python
from chat import OmniLMMChat, img2base64
chat_model = OmniLMMChat('openbmb/OmniLMM-12B') # or 'openbmb/MiniCPM-V-2'
im_64 = img2base64('./assets/hk_OCR.jpg')
# First round chat
msgs = [{"role": "user", "content": "Where should I go to buy a camera?"}]
inputs = {"image": im_64, "question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)
# Second round chat
# pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": answer})
msgs.append({"role": "user", "content": "Where is this store in the image?"})
inputs = {"image": im_64, "question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)
```
可以得到以下输出:
```
"You should go to the Canon store for a camera."
"The Canon store is located on the right side of the image."
```
### Mac 推理
点击查看 MiniCPM-V 2.0 基于Mac MPS运行 (Apple silicon or AMD GPUs)的示例。
```python
# test.py
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2.0', trust_remote_code=True, torch_dtype=torch.bfloat16)
model = model.to(device='mps', dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2.0', trust_remote_code=True)
model.eval()
image = Image.open('./assets/hk_OCR.jpg').convert('RGB')
question = 'Where is this photo taken?'
msgs = [{'role': 'user', 'content': question}]
answer, context, _ = model.chat(
image=image,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True
)
print(answer)
```
运行:
```shell
PYTORCH_ENABLE_MPS_FALLBACK=1 python test.py
```
### 手机端部署
MiniCPM-V 2.0 目前可以部署在Android和Harmony操作系统的手机上。 🚀 点击[这里](https://github.com/OpenBMB/mlc-MiniCPM)开始手机端部署。
## 未来计划
- [ ] 支持模型微调
- [ ] 本地用户图形界面部署
- [ ] 实时多模态交互代码开源
## 模型协议
本仓库中代码依照 Apache-2.0 协议开源
OmniLMM 模型权重的使用遵循 “[通用模型许可协议-来源说明-宣传限制-商业授权](https://github.com/OpenBMB/General-Model-License/blob/main/通用模型许可协议-来源说明-宣传限制-商业授权.md)”。
OmniLMM 模型权重对学术研究完全开放。
如需将模型用于商业用途,请联系 cpm@modelbest.cn 来获取书面授权,登记后可以免费商业使用。
## 声明
作为多模态大模型,MiniCPM-V 和 OmniLMM 通过学习大量的多模态数据来生成内容,但它无法理解、表达个人观点或价值判断,它所输出的任何内容都不代表模型开发者的观点和立场。
因此用户在使用 MiniCPM-V 和 OmniLMM 生成的内容时,应自行负责对其进行评估和验证。如果由于使用 OmniLMM 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
## 机构
本项目由以下机构共同开发:
-  [清华大学自然语言处理实验室](https://nlp.csai.tsinghua.edu.cn/)
-
[清华大学自然语言处理实验室](https://nlp.csai.tsinghua.edu.cn/)
-  [面壁智能](https://modelbest.cn/)
-
[面壁智能](https://modelbest.cn/)
-  [知乎](https://www.zhihu.com/ )
[知乎](https://www.zhihu.com/ )
 **性能领先且部署高效的多模态大模型**
中文 |
[English](./README_en.md)
**性能领先且部署高效的多模态大模型**
中文 |
[English](./README_en.md)