 **A GPT-4o Level MLLM for Vision, Speech and Multimodal Live Streaming on Your Phone**
[中文](./README_zh.md) |
English
**A GPT-4o Level MLLM for Vision, Speech and Multimodal Live Streaming on Your Phone**
[中文](./README_zh.md) |
English
 WeChat |
WeChat |
 Discord
Discord
MiniCPM-o 2.6 🤗 🤖 | MiniCPM-V 2.6 🤗 🤖 | 📄 Technical Blog [English/中文]
**A GPT-4o Level MLLM for Vision, Speech and Multimodal Live Streaming on Your Phone**
[中文](./README_zh.md) |
English
WeChat |
Discord
MiniCPM-o 2.6 🤗 🤖 | MiniCPM-V 2.6 🤗 🤖 | 📄 Technical Blog [English/中文]
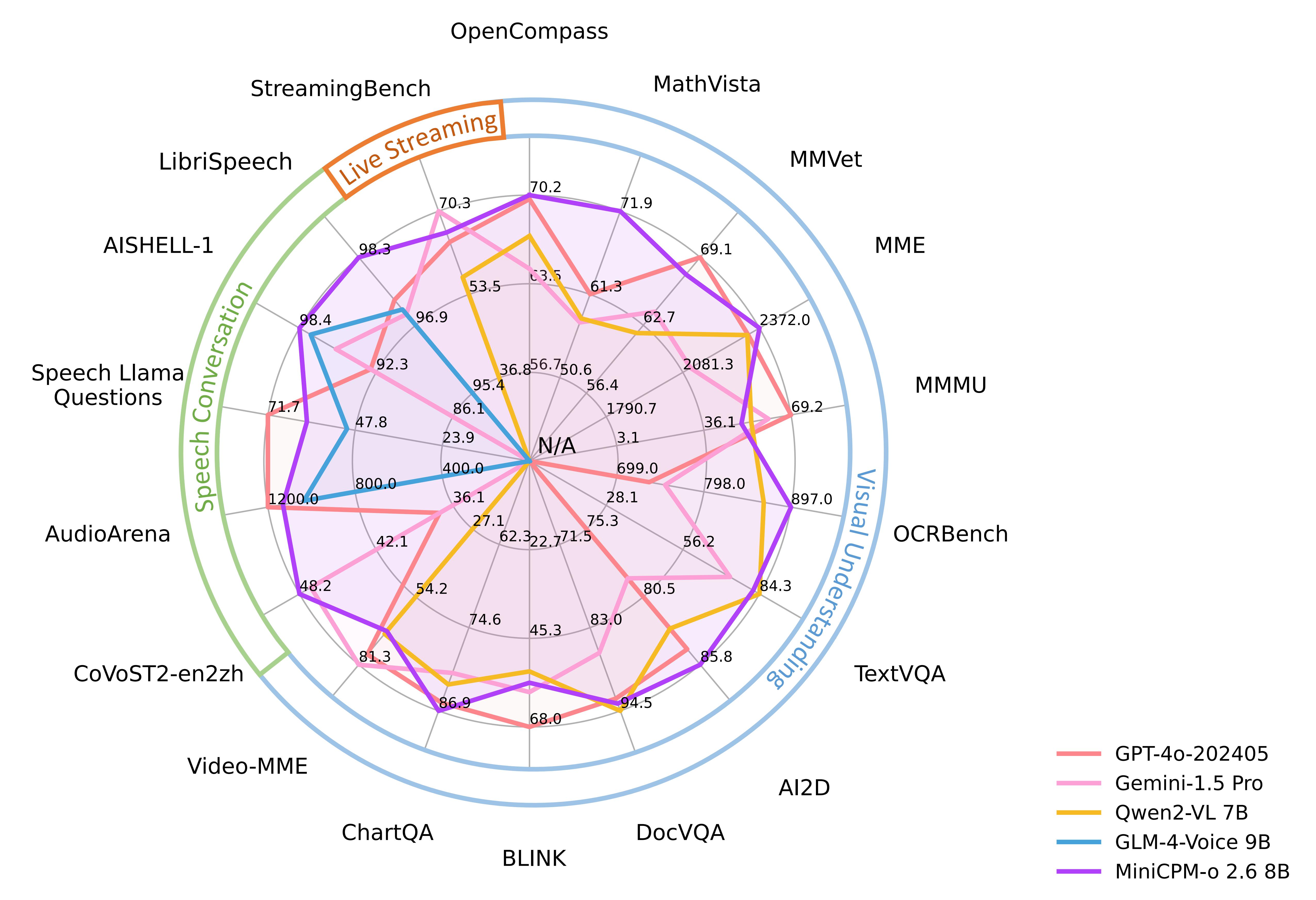
| Model | Size | Token Density+ | OpenCompass | OCRBench | MathVista mini | ChartQA | MMVet | MMStar | MME | MMB1.1 test | AI2D | MMMU val | HallusionBench | TextVQA val | DocVQA test | MathVerse mini | MathVision | MMHal Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary | ||||||||||||||||||
| GPT-4o-20240513 | - | 1088 | 69.9 | 736 | 61.3 | 85.7 | 69.1 | 63.9 | 2328.7 | 82.2 | 84.6 | 69.2 | 55.0 | - | 92.8 | 50.2 | 30.4 | 3.6 |
| Claude3.5-Sonnet | - | 750 | 67.9 | 788 | 61.6 | 90.8 | 66.0 | 62.2 | 1920.0 | 78.5 | 80.2 | 65.9 | 49.9 | - | 95.2 | - | - | 3.4 |
| Gemini 1.5 Pro | - | - | 64.4 | 754 | 57.7 | 81.3 | 64.0 | 59.1 | 2110.6 | 73.9 | 79.1 | 60.6 | 45.6 | 73.5 | 86.5 | - | 19.2 | - |
| GPT-4o-mini-20240718 | - | 1088 | 64.1 | 785 | 52.4 | - | 66.9 | 54.8 | 2003.4 | 76.0 | 77.8 | 60.0 | 46.1 | - | - | - | - | 3.3 |
| Open Source | ||||||||||||||||||
| Cambrian-34B | 34B | 1820 | 58.3 | 591 | 50.3 | 75.6 | 53.2 | 54.2 | 2049.9 | 77.8 | 79.5 | 50.4 | 41.6 | 76.7 | 75.5 | - | - | - |
| GLM-4V-9B | 13B | 784 | 59.1 | 776 | 51.1 | - | 58.0 | 54.8 | 2018.8 | 67.9 | 71.2 | 46.9 | 45.0 | - | - | - | - | - |
| Pixtral-12B | 12B | 256 | 61.0 | 685 | 56.9 | 81.8 | 58.5 | 54.5 | - | 72.7 | 79.0 | 51.1 | 47.0 | 75.7 | 90.7 | - | - | - |
| VITA-1.5 | 8B | 784 | 63.3 | 741 | 66.2 | - | 52.7 | 60.2 | 2328.1 | 76.8 | 79.2 | 52.6 | 44.6 | - | - | - | - | - |
| DeepSeek-VL2-27B (4B) | 27B | 672 | 66.4 | 809 | 63.9 | 86.0 | 60.0 | 61.9 | 2253.0 | 81.2 | 83.8 | 54.0 | 45.3 | 84.2 | 93.3 | - | - | 3.0 |
| Qwen2-VL-7B | 8B | 784 | 67.1 | 866 | 58.2 | 83.0 | 62.0 | 60.7 | 2326.0 | 81.8 | 83.0 | 54.1 | 50.6 | 84.3 | 94.5 | 31.9 | 16.3 | 3.2 |
| LLaVA-OneVision-72B | 72B | 182 | 68.1 | 741 | 67.5 | 83.7 | 60.6 | 65.8 | 2261.0 | 85.0 | 85.6 | 56.8 | 49.0 | 80.5 | 91.3 | 39.1 | - | 3.5 |
| InternVL2.5-8B | 8B | 706 | 68.3 | 822 | 64.4 | 84.8 | 62.8 | 62.8 | 2344.0 | 83.6 | 84.5 | 56.0 | 50.1 | 79.1 | 93.0 | 39.5 | 19.7 | 3.4 |
| MiniCPM-V 2.6 | 8B | 2822 | 65.2 | 852* | 60.6 | 79.4 | 60.0 | 57.5 | 2348.4* | 78.0 | 82.1 | 49.8* | 48.1* | 80.1 | 90.8 | 25.7 | 18.3 | 3.6 |
| MiniCPM-o 2.6 | 8B | 2822 | 70.2 | 897* | 71.9* | 86.9* | 67.5 | 64.0 | 2372.0* | 80.5 | 85.8 | 50.4* | 51.9 | 82.0 | 93.5 | 41.4* | 23.1* | 3.8 |
| Model | Size | BLINK val | Mantis Eval | MIRB | Video-MME (wo / w subs) |
|---|---|---|---|---|---|
| Proprietary | |||||
| GPT-4o-20240513 | - | 68.0 | - | - | 71.9/77.2 |
| GPT4V | - | 54.6 | 62.7 | 53.1 | 59.9/63.3 |
| Open-source | |||||
| VITA-1.5 | 8B | 45.0 | - | - | 56.1/58.7 |
| LLaVA-NeXT-Interleave 14B | 14B | 52.6 | 66.4 | 30.2 | - |
| LLaVA-OneVision-72B | 72B | 55.4 | 77.6 | - | 66.2/69.5 |
| MANTIS 8B | 8B | 49.1 | 59.5 | 34.8 | - |
| Qwen2-VL-7B | 8B | 53.2 | 69.6* | 67.6* | 63.3/69.0 |
| InternVL2.5-8B | 8B | 54.8 | 67.7 | 52.5 | 64.2/66.9 |
| MiniCPM-V 2.6 | 8B | 53.0 | 69.1 | 53.8 | 60.9/63.6 |
| MiniCPM-o 2.6 | 8B | 56.7 | 71.9 | 58.6 | 63.9/67.9 |
| Task | Size | ASR (zh) | ASR (en) | AST | Emotion | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | CER↓ | WER↓ | BLEU↑ | ACC↑ | ||||||
| Dataset | AISHELL-1 | Fleurs zh | WenetSpeech test-net | LibriSpeech test-clean | GigaSpeech | TED-LIUM | CoVoST en2zh | CoVoST zh2en | MELD emotion | |
| Proprietary | ||||||||||
| GPT-4o-Realtime | - | 7.3* | 5.4* | 28.9* | 2.6* | 12.9* | 4.8* | 37.1* | 15.7* | 33.2* |
| Gemini 1.5 Pro | - | 4.5* | 5.9* | 14.3* | 2.9* | 10.6* | 3.0* | 47.3* | 22.6* | 48.4* |
| Open-Source | ||||||||||
| Qwen2-Audio-7B | 8B | - | 7.5 | - | 1.6 | - | - | 45.2 | 24.4 | 55.3 |
| Qwen2-Audio-7B-Instruct | 8B | 2.6* | 6.9* | 10.3* | 3.1* | 9.7* | 5.9* | 39.5* | 22.9* | 17.4* |
| VITA-1.5 | 8B | 2.16 | - | 8.4 | 3.4 | - | - | - | - | - |
| GLM-4-Voice-Base | 9B | 2.5 | - | - | 2.8 | - | - | - | - | |
| MiniCPM-o 2.6 | 8B | 1.6 | 4.4 | 6.9 | 1.7 | 8.7 | 3.0 | 48.2 | 27.2 | 52.4 |
| Task | Size | SpeechQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | ACC↑ | G-Eval (10 point)↑ | Semantic ELO score↑ | Acoustic ELO score↑ | Overall ELO score↑ | UTMOS↑ | ASR-WER↓ | |||
| Dataset | Speech Llama Q. | Speech Web Q. | Speech Trivia QA | Speech AlpacaEval | AudioArena | |||||
| Proprietary | ||||||||||
| GPT-4o-Realtime | 71.7 | 51.6 | 69.7 | 7.4 | 1157 | 1203 | 1200 | 4.2 | 2.3 | |
| Open-Source | ||||||||||
| GLM-4-Voice | 9B | 50.0 | 32.0 | 36.4 | 5.1 | 999 | 1147 | 1035 | 4.1 | 11.7 |
| Llama-Omni | 8B | 45.3 | 22.9 | 10.7 | 3.9 | 960 | 878 | 897 | 3.2 | 24.3 |
| VITA-1.5 | 8B | 46.7 | 28.1 | 23.3 | 2.0 | - | - | - | - | - |
| Moshi | 7B | 43.7 | 23.8 | 16.7 | 2.4 | 871 | 808 | 875 | 2.8 | 8.2 |
| Mini-Omni | 1B | 22.0 | 12.8 | 6.9 | 2.5 | 926 | 803 | 865 | 3.4 | 10.0 |
| MiniCPM-o 2.6 | 8B | 61.0 | 40.0 | 40.2 | 5.1 | 1088 | 1163 | 1131 | 4.2 | 9.8 |
| Task | Voice cloning | |
|---|---|---|
| Metric | SIMO↑ | SIMO↑ |
| Dataset | Seed-TTS test-zh | Seed-TTS test-en |
| F5-TTS | 76 | 67 |
| CosyVoice | 75 | 64 |
| FireRedTTS | 63 | 46 |
| MiniCPM-o 2.6 | 57 | 47 |
| Model | Size | Real-Time Video Understanding | Omni-Source Understanding | Contextual Understanding | Overall | |||
|---|---|---|---|---|---|---|---|---|
| Proprietary | ||||||||
| Gemini 1.5 Pro | - | 77.4 | 67.8 | 51.1 | 70.3 | |||
| GPT-4o-202408 | - | 74.5 | 51.0 | 48.0 | 64.1 | |||
| Claude-3.5-Sonnet | - | 74.0 | 41.4 | 37.8 | 59.7 | |||
| Open-source | ||||||||
| VILA-1.5 | 8B | 61.5 | 37.5 | 26.7 | 49.5 | |||
| LongVA | 7B | 63.1 | 35.9 | 30.2 | 50.7 | |||
| LLaVA-Next-Video-34B | 34B | 69.8 | 41.7 | 34.3 | 56.7 | |||
| Qwen2-VL-7B | 8B | 71.2 | 40.7 | 33.1 | 57.0 | |||
| InternVL2-8B | 8B | 70.1 | 42.7 | 34.1 | 57.0 | |||
| VITA-1.5 | 8B | 70.9 | 40.8 | 35.8 | 57.4 | |||
| LLaVA-OneVision-7B | 8B | 74.3 | 40.8 | 31.0 | 58.4 | |||
| InternLM-XC2.5-OL-7B | 8B | 75.4 | 46.2 | 33.6 | 60.8 | |||
| MiniCPM-V 2.6 | 8B | 72.4 | 40.2 | 33.4 | 57.7 | |||
| MiniCPM-o 2.6 | 8B | 79.9 | 53.4 | 38.5 | 66.0 | |||





| Model | Size | Token Density+ | OpenCompass | MME | MMVet | OCRBench | MMMU val | MathVista mini | MMB1.1 test | AI2D | TextVQA val | DocVQA test | HallusionBench | Object HalBench |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary | ||||||||||||||
| GPT-4o | - | 1088 | 69.9 | 2328.7 | 69.1 | 736 | 69.2 | 61.3 | 82.2 | 84.6 | - | 92.8 | 55.0 | 17.6 |
| Claude 3.5 Sonnet | - | 750 | 67.9 | 1920.0 | 66.0 | 788 | 65.9 | 61.6 | 78.5 | 80.2 | - | 95.2 | 49.9 | 13.8 |
| Gemini 1.5 Pro | - | - | 64.4 | 2110.6 | 64.0 | 754 | 60.6 | 57.7 | 73.9 | 79.1 | 73.5 | 86.5 | 45.6 | - |
| GPT-4o mini | - | 1088 | 64.1 | 2003.4 | 66.9 | 785 | 60.0 | 52.4 | 76.0 | 77.8 | - | - | 46.1 | 12.4 |
| GPT-4V | - | 1088 | 63.5 | 2070.2 | 67.5 | 656 | 61.7 | 54.7 | 79.8 | 78.6 | 78.0 | 87.2 | 43.9 | 14.2 |
| Step-1V | - | - | 59.5 | 2206.4 | 63.3 | 625 | 49.9 | 44.8 | 78.0 | 79.2 | 71.6 | - | 48.4 | - |
| Qwen-VL-Max | - | 784 | 58.3 | 2281.7 | 61.8 | 684 | 52.0 | 43.4 | 74.6 | 75.7 | 79.5 | 93.1 | 41.2 | 13.4 |
| Open-source | ||||||||||||||
| LLaVA-NeXT-Yi-34B | 34B | 157 | 55.0 | 2006.5 | 50.7 | 574 | 48.8 | 40.4 | 77.8 | 78.9 | 69.3 | - | 34.8 | 12.6 |
| Mini-Gemini-HD-34B | 34B | 157 | - | 2141.0 | 59.3 | 518 | 48.0 | 43.3 | - | 80.5 | 74.1 | 78.9 | - | - |
| Cambrian-34B | 34B | 1820 | 58.3 | 2049.9 | 53.2 | 591 | 50.4 | 50.3 | 77.8 | 79.5 | 76.7 | 75.5 | 41.6 | 14.7 |
| GLM-4V-9B | 13B | 784 | 59.1 | 2018.8 | 58.0 | 776 | 46.9 | 51.1 | 67.9 | 71.2 | - | - | 45.0 | - |
| InternVL2-8B | 8B | 706 | 64.1 | 2215.1 | 54.3 | 794 | 51.2 | 58.3 | 79.4 | 83.6 | 77.4 | 91.6 | 45.0 | 21.3 |
| MiniCPM-Llama-V 2.5 | 8B | 1882 | 58.8 | 2024.6 | 52.8 | 725 | 45.8 | 54.3 | 72.0 | 78.4 | 76.6 | 84.8 | 42.4 | 10.3 |
| MiniCPM-V 2.6 | 8B | 2822 | 65.2 | 2348.4* | 60.0 | 852* | 49.8* | 60.6 | 78.0 | 82.1 | 80.1 | 90.8 | 48.1* | 8.2 |
| Model | Size | Mantis Eval | BLINK val | Mathverse mv | Sciverse mv | MIRB |
|---|---|---|---|---|---|---|
| Proprietary | ||||||
| GPT-4V | - | 62.7 | 54.6 | 60.3 | 66.9 | 53.1 |
| LLaVA-NeXT-Interleave-14B | 14B | 66.4 | 52.6 | 32.7 | 30.2 | - |
| Open-source | ||||||
| Emu2-Chat | 37B | 37.8 | 36.2 | - | 27.2 | - |
| CogVLM | 17B | 45.2 | 41.1 | - | - | - |
| VPG-C | 7B | 52.4 | 43.1 | 24.3 | 23.1 | - |
| VILA 8B | 8B | 51.2 | 39.3 | - | 36.5 | - |
| InternLM-XComposer-2.5 | 8B | 53.1* | 48.9 | 32.1* | - | 42.5 |
| InternVL2-8B | 8B | 59.0* | 50.9 | 30.5* | 34.4* | 56.9* |
| MiniCPM-V 2.6 | 8B | 69.1 | 53.0 | 84.9 | 74.9 | 53.8 |
| Model | Size | Video-MME | Video-ChatGPT | |||||
|---|---|---|---|---|---|---|---|---|
| w/o subs | w subs | Correctness | Detail | Context | Temporal | Consistency | ||
| Proprietary | ||||||||
| Claude 3.5 Sonnet | - | 60.0 | 62.9 | - | - | - | - | - |
| GPT-4V | - | 59.9 | 63.3 | - | - | - | - | - |
| Open-source | ||||||||
| LLaVA-NeXT-7B | 7B | - | - | 3.39 | 3.29 | 3.92 | 2.60 | 3.12 |
| LLaVA-NeXT-34B | 34B | - | - | 3.29 | 3.23 | 3.83 | 2.51 | 3.47 |
| CogVLM2-Video | 12B | - | - | 3.49 | 3.46 | 3.23 | 2.98 | 3.64 |
| LongVA | 7B | 52.4 | 54.3 | 3.05 | 3.09 | 3.77 | 2.44 | 3.64 |
| InternVL2-8B | 8B | 54.0 | 56.9 | - | - | - | - | - |
| InternLM-XComposer-2.5 | 8B | 55.8 | - | - | - | - | - | - |
| LLaVA-NeXT-Video | 32B | 60.2 | 63.0 | 3.48 | 3.37 | 3.95 | 2.64 | 3.28 |
| MiniCPM-V 2.6 | 8B | 60.9 | 63.6 | 3.59 | 3.28 | 3.93 | 2.73 | 3.62 |
| Model | Size | Shot | TextVQA val | VizWiz test-dev | VQAv2 test-dev | OK-VQA val |
|---|---|---|---|---|---|---|
| Flamingo | 80B | 0* | 35.0 | 31.6 | 56.3 | 40.6 |
| 4 | 36.5 | 39.6 | 63.1 | 57.4 | ||
| 8 | 37.3 | 44.8 | 65.6 | 57.5 | ||
| IDEFICS | 80B | 0* | 30.9 | 36.0 | 60.0 | 45.2 |
| 4 | 34.3 | 40.4 | 63.6 | 52.4 | ||
| 8 | 35.7 | 46.1 | 64.8 | 55.1 | ||
| OmniCorpus | 7B | 0* | 43.0 | 49.8 | 63.2 | 45.5 |
| 4 | 45.4 | 51.3 | 64.5 | 46.5 | ||
| 8 | 45.6 | 52.2 | 64.7 | 46.6 | ||
| Emu2 | 37B | 0 | 26.4 | 40.4 | 33.5 | 26.7 |
| 4 | 48.2 | 54.6 | 67.0 | 53.2 | ||
| 8 | 49.3 | 54.7 | 67.8 | 54.1 | ||
| MM1 | 30B | 0 | 26.2 | 40.4 | 48.9 | 26.7 |
| 8 | 49.3 | 54.7 | 70.9 | 54.1 | ||
| MiniCPM-V 2.6+ | 8B | 0 | 43.9 | 33.8 | 45.4 | 23.9 |
| 4 | 63.6 | 60.5 | 65.5 | 50.1 | ||
| 8 | 64.6 | 63.4 | 68.2 | 51.4 |




 , the most popular model deployment framework nowadays. It supports streaming outputs, progress bars, queuing, alerts, and other useful features.
### Online Demo
Click here to try out the online demo of [MiniCPM-o 2.6](https://minicpm-omni-webdemo-us.modelbest.cn/) | [MiniCPM-V 2.6](http://120.92.209.146:8887/) | [MiniCPM-Llama3-V 2.5](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5) | [MiniCPM-V 2.0](https://huggingface.co/spaces/openbmb/MiniCPM-V-2).
### Local WebUI Demo
You can easily build your own local WebUI demo using the following commands.
Please ensure that `transformers==4.44.2` is installed, as other versions may have compatibility issues.
If you are using an older version of PyTorch, you might encounter this issue `"weight_norm_fwd_first_dim_kernel" not implemented for 'BFloat16'`, Please add `self.minicpmo_model.tts.float()` during the model initialization.
**For real-time voice/video call demo:**
1. launch model server:
```shell
pip install -r requirements_o2.6.txt
python web_demos/minicpm-o_2.6/model_server.py
```
2. launch web server:
```shell
# Make sure Node and PNPM is installed.
sudo apt-get update
sudo apt-get install nodejs npm
npm install -g pnpm
cd web_demos/minicpm-o_2.6/web_server
# create ssl cert for https, https is required to request camera and microphone permissions.
bash ./make_ssl_cert.sh # output key.pem and cert.pem
pnpm install # install requirements
pnpm run dev # start server
```
Open `https://localhost:8088/` in browser and enjoy the real-time voice/video call.
**For chatbot demo:**
```shell
pip install -r requirements_o2.6.txt
python web_demos/minicpm-o_2.6/chatbot_web_demo_o2.6.py
```
Open `http://localhost:8000/` in browser and enjoy the vision mode chatbot.
## Inference
### Model Zoo
| Model | Device | Memory | Description | Download |
|:-----------|:--:|:-----------:|:-------------------|:---------------:|
| MiniCPM-o 2.6| GPU | 18 GB | The latest version, achieving GPT-4o level performance for vision, speech and multimodal live streaming on end-side devices. | [🤗](https://huggingface.co/openbmb/MiniCPM-o-2_6) [
, the most popular model deployment framework nowadays. It supports streaming outputs, progress bars, queuing, alerts, and other useful features.
### Online Demo
Click here to try out the online demo of [MiniCPM-o 2.6](https://minicpm-omni-webdemo-us.modelbest.cn/) | [MiniCPM-V 2.6](http://120.92.209.146:8887/) | [MiniCPM-Llama3-V 2.5](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5) | [MiniCPM-V 2.0](https://huggingface.co/spaces/openbmb/MiniCPM-V-2).
### Local WebUI Demo
You can easily build your own local WebUI demo using the following commands.
Please ensure that `transformers==4.44.2` is installed, as other versions may have compatibility issues.
If you are using an older version of PyTorch, you might encounter this issue `"weight_norm_fwd_first_dim_kernel" not implemented for 'BFloat16'`, Please add `self.minicpmo_model.tts.float()` during the model initialization.
**For real-time voice/video call demo:**
1. launch model server:
```shell
pip install -r requirements_o2.6.txt
python web_demos/minicpm-o_2.6/model_server.py
```
2. launch web server:
```shell
# Make sure Node and PNPM is installed.
sudo apt-get update
sudo apt-get install nodejs npm
npm install -g pnpm
cd web_demos/minicpm-o_2.6/web_server
# create ssl cert for https, https is required to request camera and microphone permissions.
bash ./make_ssl_cert.sh # output key.pem and cert.pem
pnpm install # install requirements
pnpm run dev # start server
```
Open `https://localhost:8088/` in browser and enjoy the real-time voice/video call.
**For chatbot demo:**
```shell
pip install -r requirements_o2.6.txt
python web_demos/minicpm-o_2.6/chatbot_web_demo_o2.6.py
```
Open `http://localhost:8000/` in browser and enjoy the vision mode chatbot.
## Inference
### Model Zoo
| Model | Device | Memory | Description | Download |
|:-----------|:--:|:-----------:|:-------------------|:---------------:|
| MiniCPM-o 2.6| GPU | 18 GB | The latest version, achieving GPT-4o level performance for vision, speech and multimodal live streaming on end-side devices. | [🤗](https://huggingface.co/openbmb/MiniCPM-o-2_6) [
 [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-
[THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-  [ModelBest](https://modelbest.cn/)
## 🌟 Star History
[ModelBest](https://modelbest.cn/)
## 🌟 Star History



