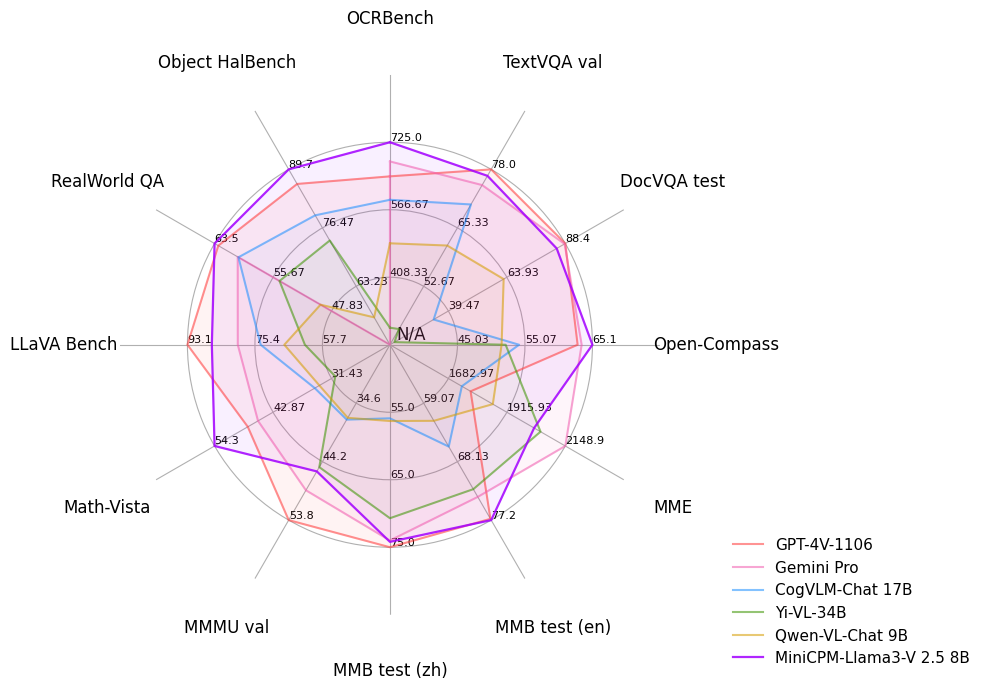
| Model | Size | OCRBench | TextVQA val | DocVQA test | Open-Compass | MME | MMB test (en) | MMB test (cn) | MMMU val | Math-Vista | LLaVA Bench | RealWorld QA | Object HalBench |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary | |||||||||||||
| Gemini Pro | - | 680 | 74.6 | 88.1 | 62.9 | 2148.9 | 73.6 | 74.3 | 48.9 | 45.8 | 79.9 | 60.4 | - |
| GPT-4V (2023.11.06) | - | 645 | 78.0 | 88.4 | 63.5 | 1771.5 | 77.0 | 74.4 | 53.8 | 47.8 | 93.1 | 63.0 | 86.4 |
| Open-source | |||||||||||||
| Mini-Gemini | 2.2B | - | 56.2 | 34.2* | - | 1653.0 | - | - | 31.7 | - | - | - | - |
| Qwen-VL-Chat | 9.6B | 488 | 61.5 | 62.6 | 51.6 | 1860.0 | 61.8 | 56.3 | 37.0 | 33.8 | 67.7 | 49.3 | 56.2 |
| DeepSeek-VL-7B | 7.3B | 435 | 64.7* | 47.0* | 54.6 | 1765.4 | 73.8 | 71.4 | 38.3 | 36.8 | 77.8 | 54.2 | - |
| Yi-VL-34B | 34B | 290 | 43.4* | 16.9* | 52.2 | 2050.2 | 72.4 | 70.7 | 45.1 | 30.7 | 62.3 | 54.8 | 79.3 |
| CogVLM-Chat | 17.4B | 590 | 70.4 | 33.3* | 54.2 | 1736.6 | 65.8 | 55.9 | 37.3 | 34.7 | 73.9 | 60.3 | 73.6 |
| TextMonkey | 9.7B | 558 | 64.3 | 66.7 | - | - | - | - | - | - | - | - | - |
| Idefics2 | 8.0B | - | 73.0 | 74.0 | 57.2 | 1847.6 | 75.7 | 68.6 | 45.2 | 52.2 | 49.1 | 60.7 | - |
| Bunny-LLama-3-8B | 8.4B | - | - | - | 54.3 | 1920.3 | 77.0 | 73.9 | 41.3 | 31.5 | 61.2 | 58.8 | - |
| LLaVA-NeXT Llama-3-8B | 8.4B | - | - | 78.2 | - | 1971.5 | - | - | 41.7 | 37.5 | 80.1 | 60.0 | - |
| Phi-3-vision-128k-instruct | 4.2B | 639* | 70.9 | - | - | 1537.5* | - | - | 40.4 | 44.5 | 64.2* | 58.8* | - |
| MiniCPM-V 1.0 | 2.8B | 366 | 60.6 | 38.2 | 47.5 | 1650.2 | 64.1 | 62.6 | 38.3 | 28.9 | 51.3 | 51.2 | 78.4 |
| MiniCPM-V 2.0 | 2.8B | 605 | 74.1 | 71.9 | 54.5 | 1808.6 | 69.1 | 66.5 | 38.2 | 38.7 | 69.2 | 55.8 | 85.5 |
| MiniCPM-Llama3-V 2.5 | 8.5B | 725 | 76.6 | 84.8 | 65.1 | 2024.6 | 77.2 | 74.2 | 45.8 | 54.3 | 86.7 | 63.5 | 89.7 |