
**A GPT-4o Level MLLM for Vision, Speech and Multimodal Live Streaming on Your Phone**
[中文](./README_zh.md) |
English
 WeChat |
WeChat |
 Discord
Discord
MiniCPM-V 4.0 🤗 🤖 | MiniCPM-o 2.6 🤗 🤖 | MiniCPM-V 2.6 🤗 🤖 | 🍳 Cookbook |
📄 Technical Blog [English/中文]
**MiniCPM-o** is the latest series of end-side multimodal LLMs (MLLMs) ungraded from MiniCPM-V. The models can now take images, video, text, and audio as inputs and provide high-quality text and speech outputs in an end-to-end fashion. Since February 2024, we have released 6 versions of the model, aiming to achieve **strong performance and efficient deployment**. The most notable models in the series currently include:
- **MiniCPM-V 4.0**: 🚀🚀🚀 The latest efficient model in the MiniCPM-V series. With a total of 4B parameters, the model **surpasses GPT-4.1-mini-20250414, Qwen2.5-VL-3B-Instruct, and InternVL2.5-8B** in image understanding on the OpenCompass evaluation. With its small parameter-size and efficient architecure, MiniCPM-V 4.0 is an ideal choice for on-device deployment on the phone (e.g., **less than 2s first token delay and more than 17 token/s decoding** on iPhone 16 Pro Max using the open-sourced iOS App).
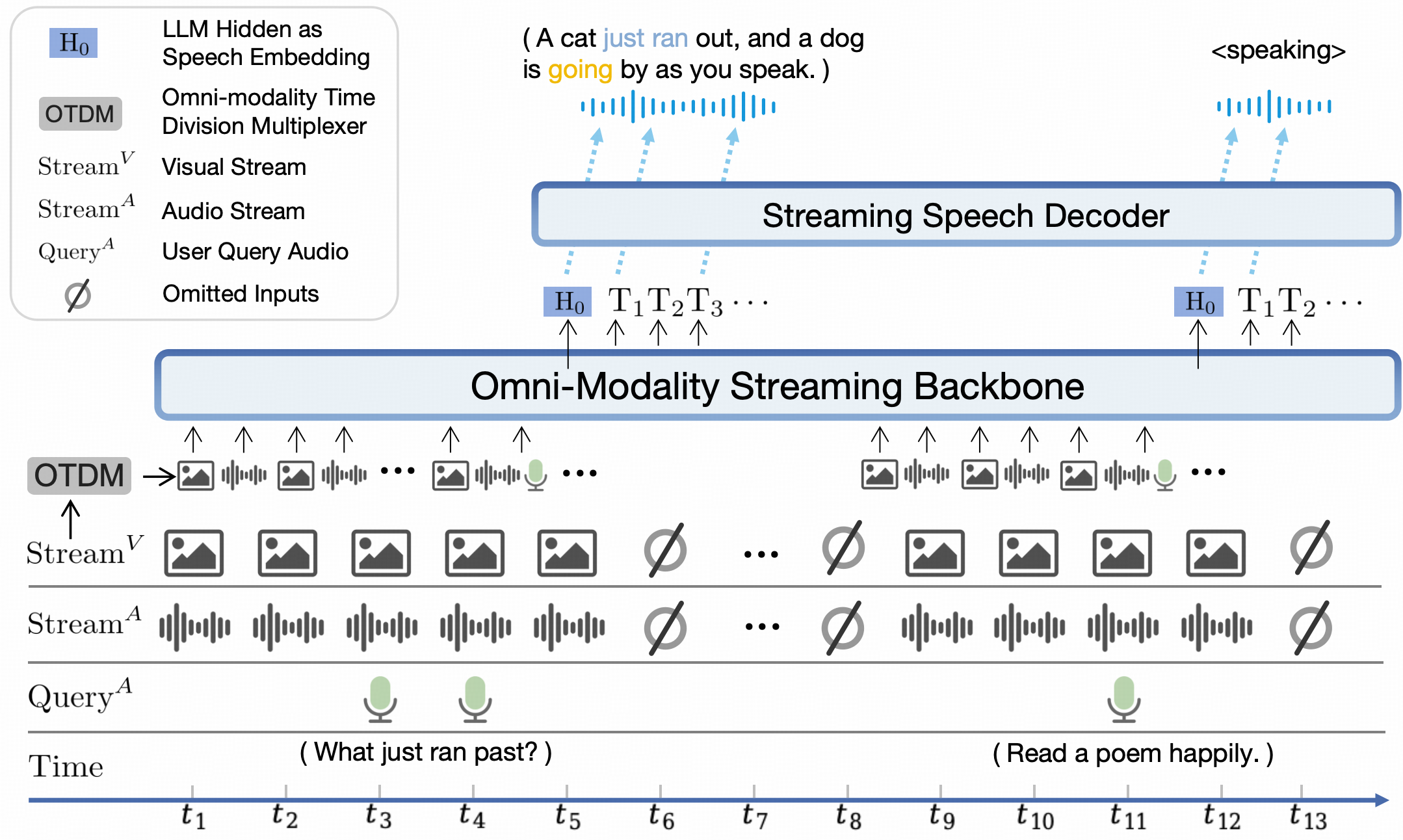
- **MiniCPM-o 2.6**: 🔥🔥🔥 The most capable model in the MiniCPM-o series. With a total of 8B parameters, this end-to-end model **achieves comparable performance to GPT-4o-202405 in vision, speech, and multimodal live streaming**, making it one of the most versatile and performant models in the open-source community. For the new voice mode, MiniCPM-o 2.6 **supports bilingual real-time speech conversation with configurable voices**, and also allows for fun capabilities such as emotion/speed/style control, end-to-end voice cloning, role play, etc. It also advances MiniCPM-V 2.6's visual capabilities such **strong OCR capability, trustworthy behavior, multilingual support, and video understanding**. Due to its superior token density, MiniCPM-o 2.6 can for the first time **support multimodal live streaming on end-side devices** such as iPad.
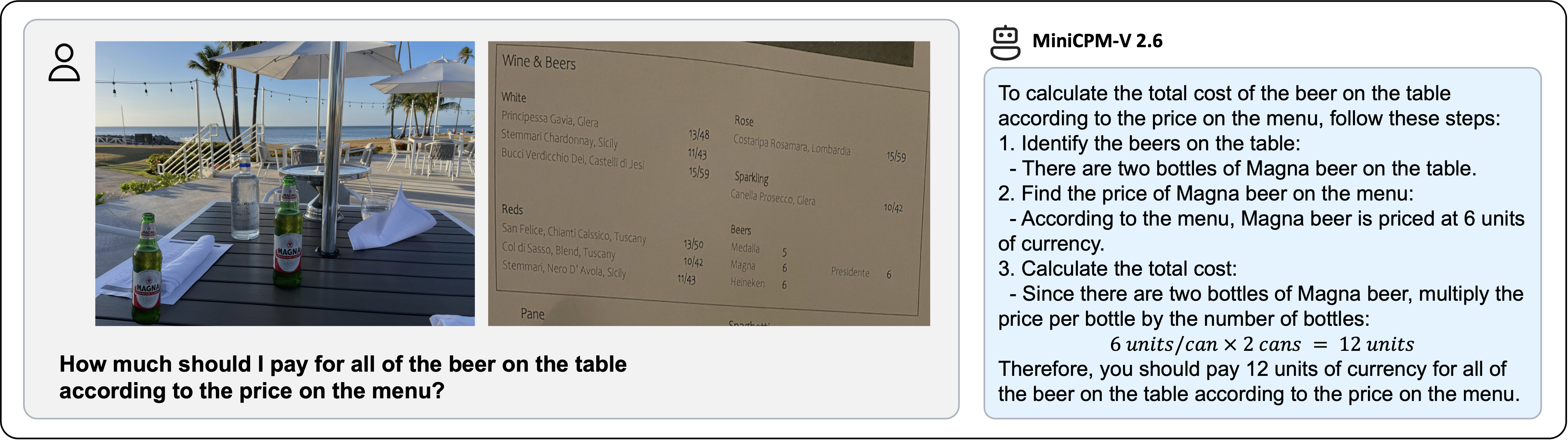
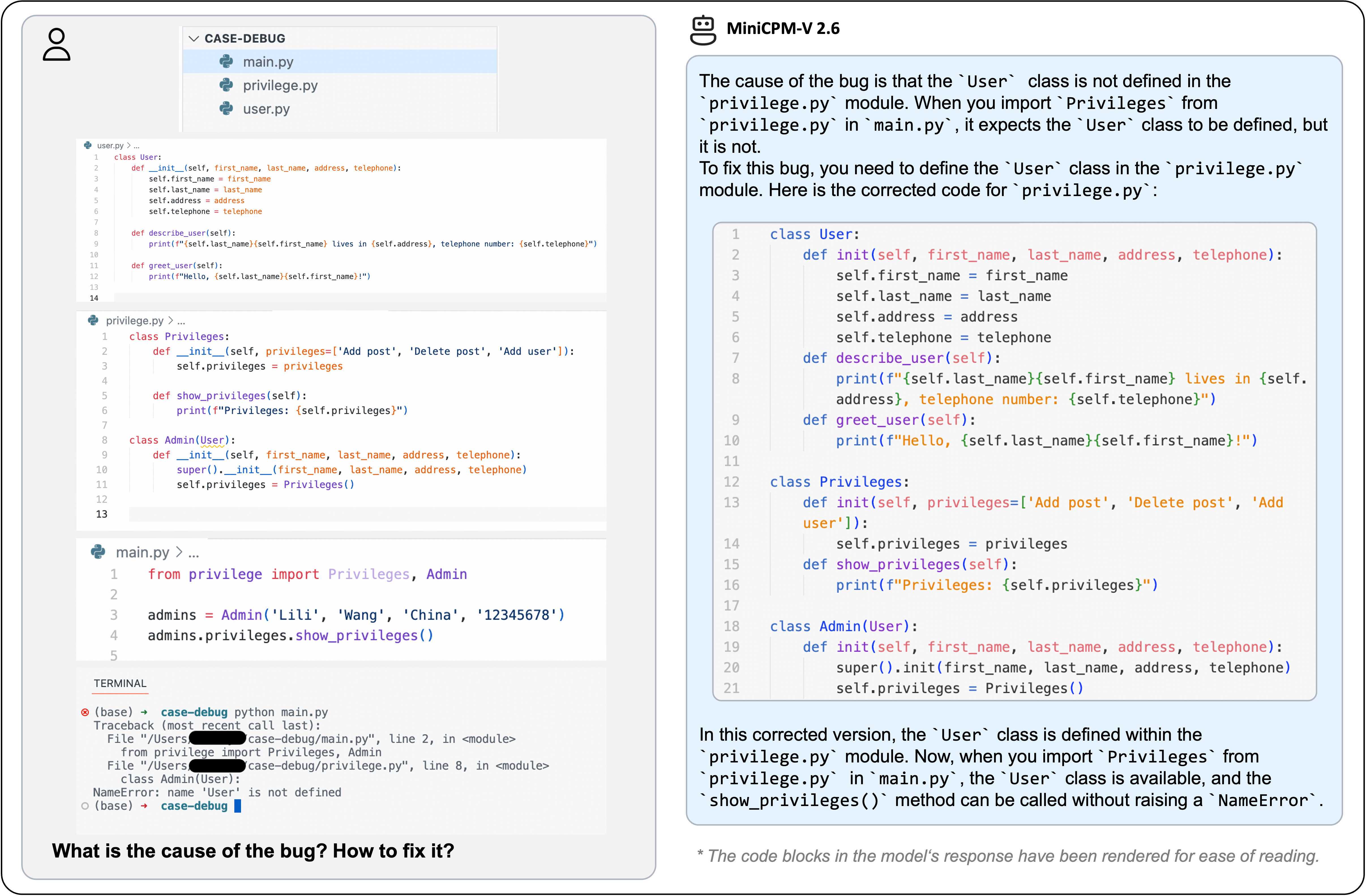
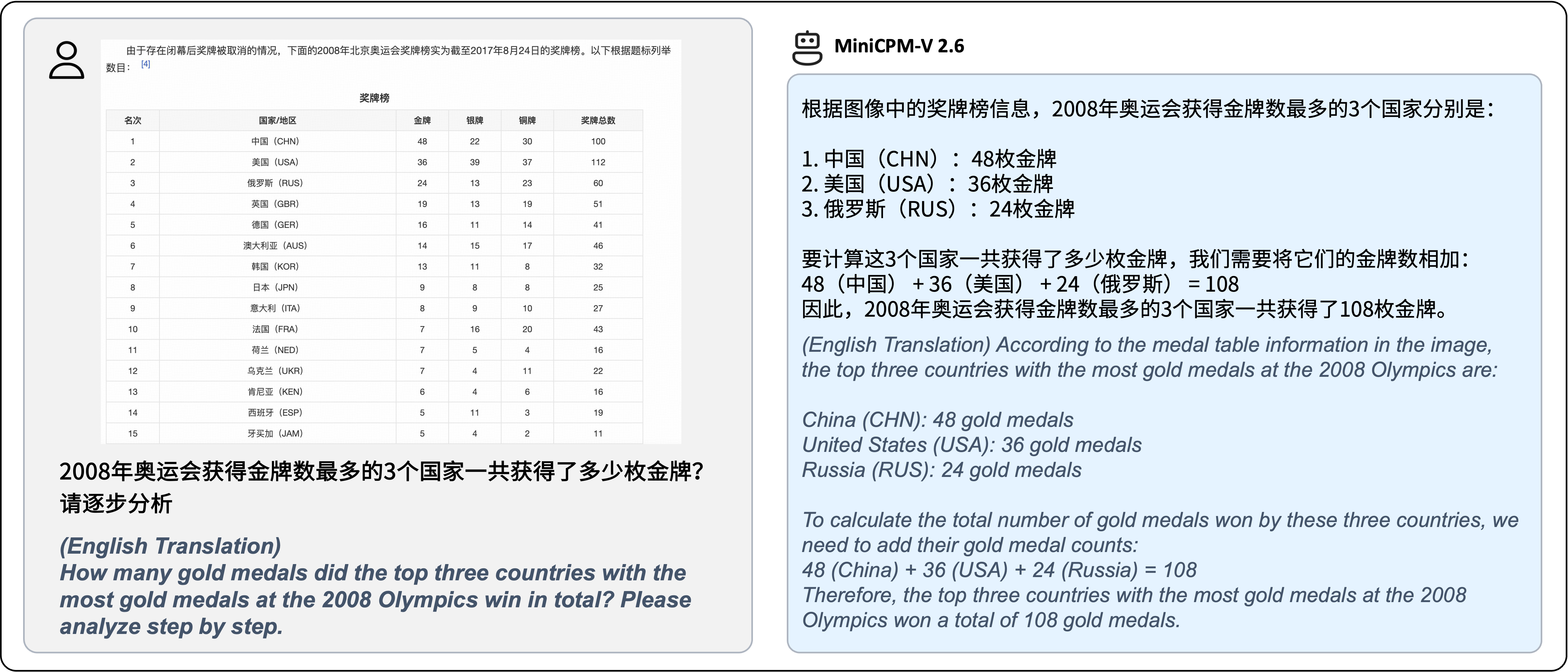
- **MiniCPM-V 2.6**: The most capable model in the MiniCPM-V series. With a total of 8B parameters, the model **surpasses GPT-4V in single-image, multi-image and video understanding**. It outperforms **GPT-4o mini, Gemini 1.5 Pro and Claude 3.5 Sonnet** in single image understanding, and can for the first time support real-time video understanding on iPad.
## News
#### 📌 Pinned
* [2025.08.02] 🚀🚀🚀 We open-source MiniCPM-V 4.0, which outperforms GPT-4.1-mini-20250414 in image understanding. It advances popular features of MiniCPM-V 2.6, and largely improves the efficiency. We also open-source the iOS App on iPhone and iPad. Try it now!
* [2025.08.01] 🔥🔥🔥 We've open-sourced the [MiniCPM-V & o Cookbook](https://github.com/OpenSQZ/MiniCPM-V-CookBook)! It provides comprehensive guides for diverse user scenarios, paired with our new [Docs Site](https://minicpm-o.readthedocs.io/en/latest/index.html) for smoother onboarding.
* [2025.06.20] ⭐️⭐️⭐️ Our official [Ollama repository](https://ollama.com/openbmb) is released. Try our latest models with [one click](https://ollama.com/openbmb/minicpm-o2.6)!
* [2025.03.01] 🚀🚀🚀 RLAIF-V, which is the alignment technique of MiniCPM-o, is accepted by CVPR 2025!The [code](https://github.com/RLHF-V/RLAIF-V), [dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset), [paper](https://arxiv.org/abs/2405.17220) are open-sourced!
* [2025.01.24] 📢📢📢 MiniCPM-o 2.6 technical report is released! See [here](https://openbmb.notion.site/MiniCPM-o-2-6-A-GPT-4o-Level-MLLM-for-Vision-Speech-and-Multimodal-Live-Streaming-on-Your-Phone-185ede1b7a558042b5d5e45e6b237da9).
* [2025.01.23] 💡💡💡 MiniCPM-o 2.6 is now supported by [Align-Anything](https://github.com/PKU-Alignment/align-anything), a framework by PKU-Alignment Team for aligning any-to-any modality large models with human intentions. It supports DPO and SFT fine-tuning on both vision and audio. Try it now!
* [2025.01.19] 📢 **ATTENTION!** We are currently working on merging MiniCPM-o 2.6 into the official repositories of llama.cpp, Ollama, and vllm. Until the merge is complete, please USE OUR LOCAL FORKS of [llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-omni/examples/llava/README-minicpmo2.6.md), [Ollama](https://github.com/OpenBMB/ollama/blob/minicpm-v2.6/examples/minicpm-v2.6/README.md), and [vllm](https://github.com/OpenBMB/MiniCPM-o?tab=readme-ov-file#efficient-inference-with-llamacpp-ollama-vllm). **Using the official repositories before the merge may lead to unexpected issues**.
* [2025.01.19] ⭐️⭐️⭐️ MiniCPM-o tops GitHub Trending and reaches top-2 on Hugging Face Trending!
* [2025.01.17] We have updated the usage of MiniCPM-o 2.6 int4 quantization version and resolved the model initialization error. Click [here](https://huggingface.co/openbmb/MiniCPM-o-2_6-int4) and try it now!
* [2025.01.13] 🔥🔥🔥 We open-source MiniCPM-o 2.6, which matches GPT-4o-202405 on vision, speech and multimodal live streaming. It advances popular capabilities of MiniCPM-V 2.6, and supports various new fun features. Try it now!
* [2024.08.17] 🚀🚀🚀 MiniCPM-V 2.6 is now fully supported by [official](https://github.com/ggerganov/llama.cpp) llama.cpp! GGUF models of various sizes are available [here](https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf).
* [2024.08.06] 🔥🔥🔥 We open-source MiniCPM-V 2.6, which outperforms GPT-4V on single image, multi-image and video understanding. It advances popular features of MiniCPM-Llama3-V 2.5, and can support real-time video understanding on iPad. Try it now!
* [2024.08.03] MiniCPM-Llama3-V 2.5 technical report is released! See [here](https://arxiv.org/abs/2408.01800).
* [2024.05.23] 🔥🔥🔥 MiniCPM-V tops GitHub Trending and Hugging Face Trending! Our demo, recommended by Hugging Face Gradio’s official account, is available [here](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5). Come and try it out!




















 [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-
[THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-  [ModelBest](https://modelbest.cn/)
## 🌟 Star History
[ModelBest](https://modelbest.cn/)
## 🌟 Star History