**MiniCPM-V** is a series of end-side multimodal LLMs (MLLMs) designed for vision-language understanding. The models take image, video and text as inputs and provide high-quality text outputs. Since February 2024, we have released 5 versions of the model, aiming to achieve **strong performance and efficient deployment**. The most notable models in this series currently include:
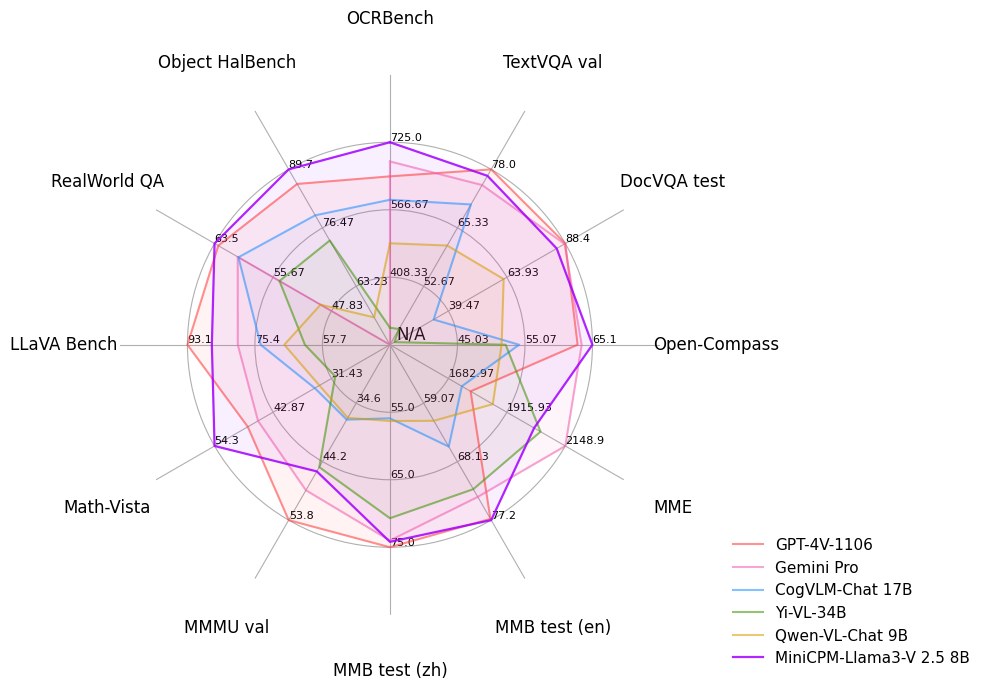
- **MiniCPM-V 2.6**: 🔥🔥🔥 The latest and most capable model in the MiniCPM-V series. With a total of 8B parameters, the model **surpasses GPT-4V in single image, multi-image and video understanding**. It outperforms **GPT-4o mini, Gemini 1.5 Pro and Claude 3.5 Sonnet** in single image understanding, and advances MiniCPM-Llama3-V 2.5's features such as strong OCR capability, trustworthy behavior, multilingual support, and end-side deployment. Due to its superior token density, MiniCPM-V 2.6 can for the first time support real-time video understanding on end-side devices such as iPad.
- **MiniCPM-V 2.0**: The lightest model in the MiniCPM-V series. With 2B parameters, it surpasses larger models such as Yi-VL 34B, CogVLM-Chat 17B, and Qwen-VL-Chat 10B in overall performance. It can accept image inputs of any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344), achieving comparable performance with Gemini Pro in understanding scene-text and matches GPT-4V in low hallucination rates.
## News
#### 📌 Pinned
* [2024.08.15] We now also support multi-image SFT. For more details, please refer to the [finetune/README.md](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune) file.
* [2024.08.14] MiniCPM-V 2.6 now also supports [fine-tuning](https://github.com/modelscope/ms-swift/issues/1613) with the SWIFT framework!
* [2024.08.10] 🚀🚀🚀 MiniCPM-Llama3-V 2.5 is now fully supported by [official](https://github.com/ggerganov/llama.cpp) llama.cpp! GGUF models of various sizes are available [here](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf).
* [2024.08.06] 🔥🔥🔥 We open-source MiniCPM-V 2.6, which outperforms GPT-4V on single image, multi-image and video understanding. It advances popular features of MiniCPM-Llama3-V 2.5, and can support real-time video understanding on iPad. Try it now!
* [2024.08.03] MiniCPM-Llama3-V 2.5 technical report is released! See [here](https://arxiv.org/abs/2408.01800).
* [2024.07.19] MiniCPM-Llama3-V 2.5 supports vLLM now! See [here](#inference-with-vllm).
* [2024.05.28] 🚀🚀🚀 MiniCPM-Llama3-V 2.5 now fully supports its feature in llama.cpp and ollama! Please pull the latest code **of our provided forks** ([llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-v2.5/examples/minicpmv/README.md), [ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.5/examples/minicpm-v2.5)). GGUF models in various sizes are available [here](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf/tree/main). MiniCPM-Llama3-V 2.5 series is **not supported by the official repositories yet**, and we are working hard to merge PRs. Please stay tuned!
* [2024.05.28] 💫 We now support LoRA fine-tuning for MiniCPM-Llama3-V 2.5, using only 2 V100 GPUs! See more statistics [here](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune#model-fine-tuning-memory-usage-statistics).
* [2024.05.23] 🔍 We've released a comprehensive comparison between Phi-3-vision-128k-instruct and MiniCPM-Llama3-V 2.5, including benchmarks evaluations, multilingual capabilities, and inference efficiency 🌟📊🌍🚀. Click [here](./docs/compare_with_phi-3_vision.md) to view more details.
* [2024.05.23] 🔥🔥🔥 MiniCPM-V tops GitHub Trending and Hugging Face Trending! Our demo, recommended by Hugging Face Gradio’s official account, is available [here](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5). Come and try it out!
 **A GPT-4V Level MLLM for Single Image, Multi Image and Video on Your Phone**
[中文](./README_zh.md) |
English
Join our 💬 WeChat
**A GPT-4V Level MLLM for Single Image, Multi Image and Video on Your Phone**
[中文](./README_zh.md) |
English
Join our 💬 WeChat







 , the most popular model deployment framework nowadays. It supports streaming outputs, progress bars, queuing, alerts, and other useful features.
### Online Demo
Click here to try out the online demo of [MiniCPM-V 2.6](https://huggingface.co/spaces/openbmb/MiniCPM-V-2_6) | [MiniCPM-Llama3-V 2.5](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5) | [MiniCPM-V 2.0](https://huggingface.co/spaces/openbmb/MiniCPM-V-2).
### Local WebUI Demo
You can easily build your own local WebUI demo with Gradio using the following commands.
```shell
pip install -r requirements.txt
```
```shell
# For NVIDIA GPUs, run:
python web_demo_2.6.py --device cuda
```
## Install
1. Clone this repository and navigate to the source folder
```bash
git clone https://github.com/OpenBMB/MiniCPM-V.git
cd MiniCPM-V
```
2. Create conda environment
```Shell
conda create -n MiniCPM-V python=3.10 -y
conda activate MiniCPM-V
```
3. Install dependencies
```shell
pip install -r requirements.txt
```
## Inference
### Model Zoo
| Model | Device | Memory | Description | Download |
|:-----------|:--:|:-----------:|:-------------------|:---------------:|
| MiniCPM-V 2.6| GPU | 17 GB | The latest version, achieving state-of-the-art end-side performance for single image, multi-image and video understanding. | [🤗](https://huggingface.co/openbmb/MiniCPM-V-2_6) [
, the most popular model deployment framework nowadays. It supports streaming outputs, progress bars, queuing, alerts, and other useful features.
### Online Demo
Click here to try out the online demo of [MiniCPM-V 2.6](https://huggingface.co/spaces/openbmb/MiniCPM-V-2_6) | [MiniCPM-Llama3-V 2.5](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5) | [MiniCPM-V 2.0](https://huggingface.co/spaces/openbmb/MiniCPM-V-2).
### Local WebUI Demo
You can easily build your own local WebUI demo with Gradio using the following commands.
```shell
pip install -r requirements.txt
```
```shell
# For NVIDIA GPUs, run:
python web_demo_2.6.py --device cuda
```
## Install
1. Clone this repository and navigate to the source folder
```bash
git clone https://github.com/OpenBMB/MiniCPM-V.git
cd MiniCPM-V
```
2. Create conda environment
```Shell
conda create -n MiniCPM-V python=3.10 -y
conda activate MiniCPM-V
```
3. Install dependencies
```shell
pip install -r requirements.txt
```
## Inference
### Model Zoo
| Model | Device | Memory | Description | Download |
|:-----------|:--:|:-----------:|:-------------------|:---------------:|
| MiniCPM-V 2.6| GPU | 17 GB | The latest version, achieving state-of-the-art end-side performance for single image, multi-image and video understanding. | [🤗](https://huggingface.co/openbmb/MiniCPM-V-2_6) [
 [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-
[THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-  [ModelBest](https://modelbest.cn/)
-
[ModelBest](https://modelbest.cn/)
-  [Zhihu](https://www.zhihu.com/ )
## 🌟 Star History
[Zhihu](https://www.zhihu.com/ )
## 🌟 Star History








