
**A GPT-4V Level Multimodal LLM on Your Phone**
[中文](./README.md) |
English
MiniCPM-Llama3-V 2.5 🤗 🤖 |
MiniCPM-V 2.0 🤗 🤖 |
Technical Blog
**MiniCPM-V** is a series of end-side multimodal LLMs designed for image-text understanding. These models accept image and text inputs and provide high-quality text outputs. Since February 2024, we have released four versions of the model, aiming to achieve **strong performance and efficient deployment**. The most noteworthy models in this series currently include:
- **MiniCPM-Llama3-V 2.5**: 🔥🔥🔥 The latest and most capable model in the MiniCPM-V series. With a total of 8B parameters, the model surpasses proprietary models such as GPT-4V-1106, Gemini Pro, Qwen-VL-Max and Claude 3 in overall performance. Its OCR capability and instruction-following capability have been further enhanced. The model supports multimodal interaction in over 30 languages including English, Chinese, French, Spanish, German etc. Equipped with model quantization and efficient inference technologies on CPUs, NPUs and compilation optimizations, MiniCPM-Llama3-V 2.5 can be efficiently deployed on edge devices.
- **MiniCPM-V 2.0**: The lightest model in the MiniCPM-V series. With 2B parameters, it surpasses larger-scale models such as Yi-VL 34B, CogVLM-Chat 17B, and Qwen-VL-Chat 10B in overall performance. It accepts image inputs of any aspect ratio up to 1.8 million pixels (e.g., 1344x1344), achieving comparable performance with Gemini Pro in understanding scene-text and matches GPT-4V in preventing hallucinations.
## News
* [2024.05.20] We open-soure MiniCPM-Llama3-V 2.5, it has improved OCR capability and supports 30+ languages, representing the first edge-side multimodal LLM achieving GPT-4V level performance! We provide [efficient inference](#deployment-on-mobile-phone) and [simple fine-tuning](./finetune/readme.md), try it now!
* [2024.04.23] MiniCPM-V-2.0 supports vLLM now! Click [here](#vllm) to view more details.
* [2024.04.18] We create a HuggingFace Space to host the demo of MiniCPM-V 2.0 at [here](https://huggingface.co/spaces/openbmb/MiniCPM-V-2)!
* [2024.04.17] MiniCPM-V-2.0 supports deploying [WebUI Demo](#webui-demo) now!
* [2024.04.15] MiniCPM-V-2.0 now also supports [fine-tuning](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2最佳实践.md) with the SWIFT framework!
* [2024.04.12] We open-source MiniCPM-V-2.0, which achieves comparable performance with Gemini Pro in understanding scene text and outperforms strong Qwen-VL-Chat 9.6B and Yi-VL 34B on OpenCompass, a comprehensive evaluation over 11 popular benchmarks. Click here to view the MiniCPM-V 2.0 technical blog.
* [2024.03.14] MiniCPM-V now supports [fine-tuning](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md) with the SWIFT framework. Thanks to [Jintao](https://github.com/Jintao-Huang) for the contribution!
* [2024.03.01] MiniCPM-V now can be deployed on Mac!
* [2024.02.01] We open-source MiniCPM-V and OmniLMM-12B, which support efficient end-side deployment and powerful multimodal capabilities correspondingly.
## Contents
- [MiniCPM-Llama3-V 2.5](#minicpm-llama3-v-25)
- [MiniCPM-V 2.0](#minicpm-v-20)
- [Online Demo](#online-demo)
- [Install](#install)
- [Inference](#inference)
- [Model Zoo](#model-zoo)
- [Multi-turn Conversation](#multi-turn-conversation)
- [Inference on Mac](#inference-on-mac)
- [Deployment on Mobile Phone](#deployment-on-mobile-phone)
- [WebUI Demo](#webui-demo)
- [Inference with vLLM](#inference-with-vllm)
- [Fine-tuning](#fine-tuning)
- [TODO](#todo)
- [Citation](#citation)
## MiniCPM-Llama3-V 2.5
**MiniCPM-Llama3-V 2.5** is the latest model in the MiniCPM-V series. The model is built on SigLip-400M and Llama3-8B-Instruct with a total of 8B parameters. It exhibits a significant performance improvement over MiniCPM-V 2.0. Notable features of MiniCPM-Llama3-V 2.5 include:
- 🔥 **Leading Performance.**
MiniCPM-Llama3-V 2.5 has achieved an average score of 65.1 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks. **It surpasses widely used proprietary models like GPT-4V-1106, Gemini Pro, Claude 3 and Qwen-VL-Max with 8B parameters**, greatly outperforming other multimodal LLMs built on Llama 3.
- 💪 **Strong OCR Capabilities.**
MiniCPM-Llama3-V 2.5 can process images with any aspect ratio up to 1.8 million pixels, achieving an **700+ score on OCRBench, surpassing proprietary models such as GPT-4o, GPT-4V-0409, Qwen-VL-Max and Gemini Pro**. Based on recent user feedback, MiniCPM-Llama3-V 2.5 has now enhanced full-text OCR extraction, table-to-markdown conversion, and other high-utility capabilities, and has further strengthened its instruction-following and complex reasoning abilities, enhancing multimodal interaction experiences.
- 🏆 **Trustworthy Behavior.**
Leveraging the latest [RLAIF-V](https://github.com/RLHF-V/RLAIF-V/) method (the newest technology in the [RLHF-V](https://github.com/RLHF-V) [CVPR'24] series), MiniCPM-Llama3-V 2.5 exhibits trustworthy multimodal behavior. It achieves **10.3%** hallucination rate on Object HalBench, lower than GPT-4V-1106 (13.6%), achieving the best level within the open-source community.
- 🌏 **Multilingual Support.**
Thanks to the strong multilingual capabilities of Llama 3 and the cross-lingual generalization technique from [VisCPM](https://github.com/OpenBMB/VisCPM), MiniCPM-Llama3-V 2.5 extends its foundational bilingual (Chinese-English) multimodal capabilities to support **30+ languages including German, French, Spanish, Italian, Russian etc.** We achieve this extension through only minimal instruction-tuning with translated multimodal data. [All Supported Languages](./assets/minicpm-llama-v-2-5_languages.md).
- 🚀 **Efficient Deployment.**
MiniCPM-Llama3-V 2.5 systematically employs **model quantization, CPU optimizations, NPU optimizations and compilation optimizations** as acceleration techniques, achieving high-efficiency deployment on edge devices. For mobile phones with Qualcomm chips, we have integrated the NPU acceleration framework QNN into llama.cpp for the first time. After systematic optimization, MiniCPM-Llama3-V 2.5 has realized a **150-fold acceleration in multimodal large model edge-side image encoding** and a **3-fold increase in language decoding speed**.
### Evaluation

Click to view results on TextVQA, DocVQA, OCRBench, OpenCompass, MME, MMBench, MMMU, MathVista, LLaVA Bench, RealWorld QA, Object HalBench.
| Model |
Size |
OCRBench |
TextVQA val |
DocVQA test |
Open-Compass |
MME |
MMB test (en) |
MMB test (cn) |
MMMU val |
Math-Vista |
LLaVA Bench |
RealWorld QA |
Object HalBench |
| Proprietary |
| Gemini Pro |
- |
680 |
74.6 |
88.1 |
62.9 |
2148.9 |
73.6 |
74.3 |
48.9 |
45.8 |
79.9 |
60.4 |
- |
| GPT-4V (2023.11.06) |
- |
645 |
78.0 |
88.4 |
63.5 |
1771.5 |
77.0 |
74.4 |
53.8 |
47.8 |
93.1 |
63.0 |
86.4 |
| Open-source |
| Mini-Gemini |
2.2B |
- |
56.2 |
34.2* |
- |
1653.0 |
- |
- |
31.7 |
- |
- |
- |
- |
| Qwen-VL-Chat |
9.6B |
488 |
61.5 |
62.6 |
51.6 |
1860.0 |
61.8 |
56.3 |
37.0 |
33.8 |
67.7 |
49.3 |
56.2 |
| DeepSeek-VL-7B |
7.3B |
435 |
64.7* |
47.0* |
54.6 |
1765.4 |
73.8 |
71.4 |
38.3 |
36.8 |
77.8 |
54.2 |
|
| Yi-VL-34B |
34B |
290 |
43.4* |
16.9* |
52.2 |
2050.2 |
72.4 |
70.7 |
45.1 |
30.7 |
62.3 |
54.8 |
79.3 |
| CogVLM-Chat |
17.4B |
590 |
70.4 |
33.3* |
54.2 |
1736.6 |
65.8 |
55.9 |
37.3 |
34.7 |
73.9 |
60.3 |
73.6 |
| TextMonkey |
9.7B |
558 |
64.3 |
66.7 |
- |
- |
- |
- |
- |
- |
- |
- |
- |
| IDEFICS2-8B |
8.0B |
- |
73.0 |
74.0 |
57.2 |
1847.6 |
75.7 |
68.6 |
45.2 |
52.2 |
49.1 |
60.7 |
- |
| Bunny-LLama-3-8B |
8.4B |
- |
- |
- |
54.3 |
1920.3 |
77.0 |
73.9 |
41.3 |
31.5 |
61.2 |
58.8 |
- |
| LLaVA-NeXT Llama-3-8B |
8.4B |
- |
- |
78.2 |
- |
1971.5 |
- |
- |
41.7 |
37.5 |
80.1 |
60.0 |
- |
| MiniCPM-V 1.0 |
2.8B |
366 |
60.6 |
38.2 |
47.5 |
1650.2 |
64.1 |
62.6 |
38.3 |
28.9 |
51.3 |
51.2 |
78.4 |
| MiniCPM-V 2.0 |
2.8B |
605 |
74.1 |
71.9 |
54.5 |
1808.6 |
69.1 |
66.5 |
38.2 |
38.7 |
69.2 |
55.8 |
85.5 |
| MiniCPM-Llama3-V 2.5 |
8.5B |
725 |
76.6 |
84.8 |
65.1 |
2024.6 |
77.2 |
74.2 |
45.8 |
54.3 |
86.7 |
63.5 |
89.7 |
* We evaluate the officially released checkpoint by ourselves.
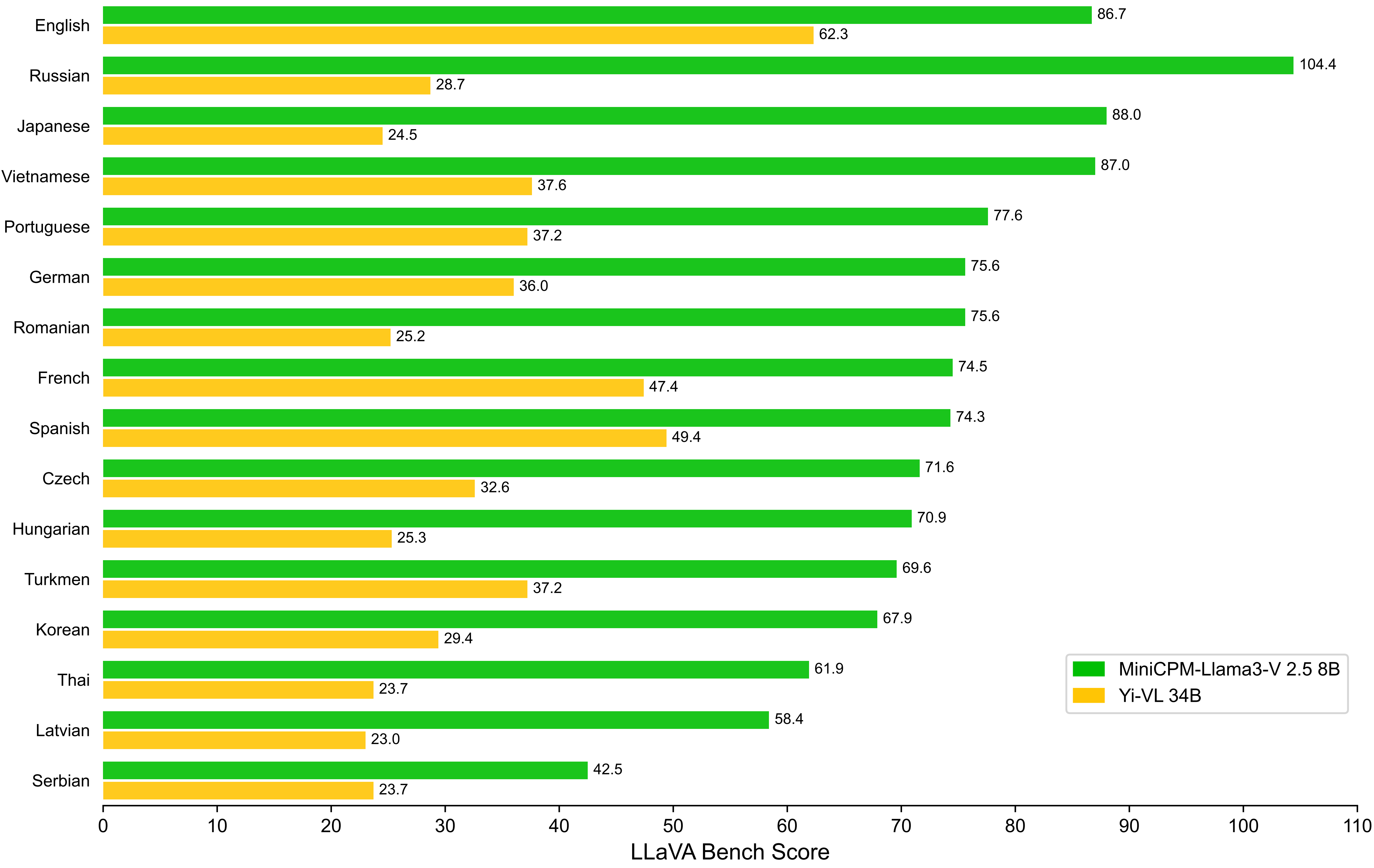
Evaluation results of LLaVABench in multiple languages
### Examples

We deploy MiniCPM-Llama3-V 2.5 on end devices. The demo video is the raw screen recording on a Xiaomi 14 Pro at double speed.



## MiniCPM-V 2.0
Click to view more details of MiniCPM-V 2.0
**MiniCPM-V 2.0** is an efficient version with promising performance for deployment. The model is built based on SigLip-400M and [MiniCPM-2.4B](https://github.com/OpenBMB/MiniCPM/), connected by a perceiver resampler. Our latest version, MiniCPM-V 2.0 has several notable features.
- 🔥 **State-of-the-art Performance.**
MiniCPM-V 2.0 achieves **state-of-the-art performance** on multiple benchmarks (including OCRBench, TextVQA, MME, MMB, MathVista, etc) among models under 7B parameters. It even **outperforms strong Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on OpenCompass, a comprehensive evaluation over 11 popular benchmarks**. Notably, MiniCPM-V 2.0 shows **strong OCR capability**, achieving **comparable performance to Gemini Pro in scene-text understanding**, and **state-of-the-art performance on OCRBench** among open-source models.
- 🏆 **Trustworthy Behavior.**
LMMs are known for suffering from hallucination, often generating text not factually grounded in images. MiniCPM-V 2.0 is **the first end-side LMM aligned via multimodal RLHF for trustworthy behavior** (using the recent [RLHF-V](https://rlhf-v.github.io/) [CVPR'24] series technique). This allows the model to **match GPT-4V in preventing hallucinations** on Object HalBench.
- 🌟 **High-Resolution Images at Any Aspect Raito.**
MiniCPM-V 2.0 can accept **1.8 million pixels (e.g., 1344x1344) images at any aspect ratio**. This enables better perception of fine-grained visual information such as small objects and optical characters, which is achieved via a recent technique from [LLaVA-UHD](https://arxiv.org/pdf/2403.11703.pdf).
- ⚡️ **High Efficiency.**
MiniCPM-V 2.0 can be **efficiently deployed on most GPU cards and personal computers**, and **even on end devices such as mobile phones**. For visual encoding, we compress the image representations into much fewer tokens via a perceiver resampler. This allows MiniCPM-V 2.0 to operate with **favorable memory cost and speed during inference even when dealing with high-resolution images**.
- 🙌 **Bilingual Support.**
MiniCPM-V 2.0 **supports strong bilingual multimodal capabilities in both English and Chinese**. This is enabled by generalizing multimodal capabilities across languages, a technique from [VisCPM](https://arxiv.org/abs/2308.12038) [ICLR'24].
### Examples
We deploy MiniCPM-V 2.0 on end devices. The demo video is the raw screen recording on a Xiaomi 14 Pro without edition.
## Legacy Models
| Model | Introduction and Guidance |
|:----------------------|:-------------------:|
| MiniCPM-V 1.0 | [Document](./minicpm_v1.md) |
| OmniLMM-12B | [Document](./omnilmm_en.md) |
## Online Demo
Click here to try out the Demo of [MiniCPM-Llama3-V 2.5](http://120.92.209.146:8889/) | [MiniCPM-V 2.0](http://120.92.209.146:80).
## Install
1. Clone this repository and navigate to the source folder
```bash
git clone https://github.com/OpenBMB/MiniCPM-V.git
cd MiniCPM-V
```
2. Create conda environment
```Shell
conda create -n MiniCPM-V python=3.10 -y
conda activate MiniCPM-V
```
3. Install dependencies
```shell
pip install -r requirements.txt
```
## Inference
### Model Zoo
| Model | Description | Download Link |
|:----------------------|:-------------------|:---------------:|
| MiniCPM-Llama3-V 2.5 | The lastest version, achieving state-of-the edge-side multimodal performance. | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5/) [ ](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5/files) |
| MiniCPM-Llama3-V 2.5 int4 | int4 quantized version,lower GPU memory usage. | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-int4/) [](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5-int4/files) |
| MiniCPM-V 2.0 | Light version, balance the performance the computation cost. | [🤗](https://huggingface.co/openbmb/MiniCPM-V-2) [](https://modelscope.cn/models/OpenBMB/MiniCPM-V-2/files) |
| MiniCPM-V 1.0 | Lightest version, achieving the fastest inference. | [🤗](https://huggingface.co/openbmb/MiniCPM-V) [](https://modelscope.cn/models/OpenBMB/MiniCPM-V/files) |
### Multi-turn Conversation
Please refer to the following codes to run `MiniCPM-V` and `OmniLMM`.
](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5/files) |
| MiniCPM-Llama3-V 2.5 int4 | int4 quantized version,lower GPU memory usage. | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-int4/) [](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5-int4/files) |
| MiniCPM-V 2.0 | Light version, balance the performance the computation cost. | [🤗](https://huggingface.co/openbmb/MiniCPM-V-2) [](https://modelscope.cn/models/OpenBMB/MiniCPM-V-2/files) |
| MiniCPM-V 1.0 | Lightest version, achieving the fastest inference. | [🤗](https://huggingface.co/openbmb/MiniCPM-V) [](https://modelscope.cn/models/OpenBMB/MiniCPM-V/files) |
### Multi-turn Conversation
Please refer to the following codes to run `MiniCPM-V` and `OmniLMM`.

```python
import torch
from chat import OmniLMMChat, img2base64
torch.manual_seed(20)
chat_model = OmniLMMChat('openbmb/MiniCPM-Llama3-V-2_5')
im_64 = img2base64('./assets/hk_OCR.jpg')
# First round chat
msgs = [{"role": "user", "content": "Where should I go to buy a camera?"}]
inputs = {"image": im_64, "question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)
# Second round chat
# pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": answer})
msgs.append({"role": "user", "content": "请用中文回答"})
inputs = {"image": im_64, "question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)
```
We can obtain the following results:
```
"You should go to the Nikon store, as indicated by the neon sign on the right side of the image."
"你应该去到尼康店,正如指示在图片的右侧。"
```
### Inference on Mac
Click to view an example, to run MiniCPM-Llama3-V 2.5 on 💻 Mac with MPS (Apple silicon or AMD GPUs).
```python
# test.py Need more than 16GB memory.
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True, low_cpu_mem_usage=True)
model = model.to(device='mps')
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True)
model.eval()
image = Image.open('./assets/hk_OCR.jpg').convert('RGB')
question = 'Where is this photo taken?'
msgs = [{'role': 'user', 'content': question}]
answer, context, _ = model.chat(
image=image,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True
)
print(answer)
```
Run with command:
```shell
PYTORCH_ENABLE_MPS_FALLBACK=1 python test.py
```
### Deployment on Mobile Phone
MiniCPM-V 2.0 can be deployed on mobile phones with Android operating systems. 🚀 Click [here](https://github.com/OpenBMB/mlc-MiniCPM) to install apk. MiniCPM-Llama3-V 2.5 coming soon.
### WebUI Demo
Click to see how to deploy WebUI demo on different devices
```shell
pip install -r requirements.txt
```
```shell
# For NVIDIA GPUs, run:
python web_demo_2.5.py --device cuda
# For Mac with MPS (Apple silicon or AMD GPUs), run:
PYTORCH_ENABLE_MPS_FALLBACK=1 python web_demo_2.5.py --device mps
```
### Inference with vLLM
Click to see how to inference with vLLM
Because our pull request to vLLM is still waiting for reviewing, we fork this repository to build and test our vLLM demo. Here are the steps:
1. Clone our version of vLLM:
```shell
git clone https://github.com/OpenBMB/vllm.git
```
2. Install vLLM:
```shell
cd vllm
pip install -e .
```
3. Install timm:
```shell
pip install timm=0.9.10
```
4. Run our demo:
```shell
python examples/minicpmv_example.py
```
## Fine-tuning
### Simple Fine-tuning
We supports simple fine-tuning with Hugging Face for MiniCPM-V 2.0 and MiniCPM-Llama3-V 2.5.
[Reference Document](./finetune/readme.md)
### With the SWIFT Framework
We now support finetune MiniCPM-V series with the SWIFT framework. SWIFT supports training, inference, evaluation and deployment of nearly 200 LLMs and MLLMs . It supports the lightweight training solutions provided by PEFT and a complete Adapters Library including techniques such as NEFTune, LoRA+ and LLaMA-PRO.
Best Practices:[MiniCPM-V 1.0](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md), [MiniCPM-V 2.0](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2最佳实践.md)
## TODO
- [x] MiniCPM-V fine-tuning support
- [ ] Code release for real-time interactive assistant
## Model License
The code in this repo is released according to [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE)
The usage of MiniCPM-V's and OmniLMM's parameters is subject to "[General Model License Agreement - Source Notes - Publicity Restrictions - Commercial License](https://github.com/OpenBMB/General-Model-License/blob/main/通用模型许可协议-来源说明-宣传限制-商业授权.md)"
The parameters are fully open to academic research
Please contact cpm@modelbest.cn to obtain written authorization for commercial uses. Free commercial use is also allowed after registration.
## Statement
As LMMs, OmniLMMs generate contents by learning a large amount of multimodal corpora, but they cannot comprehend, express personal opinions or make value judgement. Anything generated by OmniLMMs does not represent the views and positions of the model developers
We will not be liable for any problems arising from the use of OmniLMM open source models, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
## Institutions
This project is developed by the following institutions:
-  [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-
[THUNLP](https://nlp.csai.tsinghua.edu.cn/)
-  [ModelBest](https://modelbest.cn/)
-
[ModelBest](https://modelbest.cn/)
-  [Zhihu](https://www.zhihu.com/ )
## Other Multimodal Projects from Our Team
👏 Welcome to explore other multimodal projects of our team:
[VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD)
## Citation
If you find your model/code/paper helpful, please consider cite the following papers:
```bib
@article{yu2023rlhf,
title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback},
author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others},
journal={arXiv preprint arXiv:2312.00849},
year={2023}
}
@article{viscpm,
title={Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages},
author={Jinyi Hu and Yuan Yao and Chongyi Wang and Shan Wang and Yinxu Pan and Qianyu Chen and Tianyu Yu and Hanghao Wu and Yue Zhao and Haoye Zhang and Xu Han and Yankai Lin and Jiao Xue and Dahai Li and Zhiyuan Liu and Maosong Sun},
journal={arXiv preprint arXiv:2308.12038},
year={2023}
}
@article{xu2024llava-uhd,
title={{LLaVA-UHD}: an LMM Perceiving Any Aspect Ratio and High-Resolution Images},
author={Xu, Ruyi and Yao, Yuan and Guo, Zonghao and Cui, Junbo and Ni, Zanlin and Ge, Chunjiang and Chua, Tat-Seng and Liu, Zhiyuan and Huang, Gao},
journal={arXiv preprint arXiv:2403.11703},
year={2024}
}
```
[Zhihu](https://www.zhihu.com/ )
## Other Multimodal Projects from Our Team
👏 Welcome to explore other multimodal projects of our team:
[VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD)
## Citation
If you find your model/code/paper helpful, please consider cite the following papers:
```bib
@article{yu2023rlhf,
title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback},
author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others},
journal={arXiv preprint arXiv:2312.00849},
year={2023}
}
@article{viscpm,
title={Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages},
author={Jinyi Hu and Yuan Yao and Chongyi Wang and Shan Wang and Yinxu Pan and Qianyu Chen and Tianyu Yu and Hanghao Wu and Yue Zhao and Haoye Zhang and Xu Han and Yankai Lin and Jiao Xue and Dahai Li and Zhiyuan Liu and Maosong Sun},
journal={arXiv preprint arXiv:2308.12038},
year={2023}
}
@article{xu2024llava-uhd,
title={{LLaVA-UHD}: an LMM Perceiving Any Aspect Ratio and High-Resolution Images},
author={Xu, Ruyi and Yao, Yuan and Guo, Zonghao and Cui, Junbo and Ni, Zanlin and Ge, Chunjiang and Chua, Tat-Seng and Liu, Zhiyuan and Huang, Gao},
journal={arXiv preprint arXiv:2403.11703},
year={2024}
}
```


